






Na umělé inteligenci, respektive používání neuronových sítí, které se pod tímto označením (nebo také pod označením „deep learning“) rozumí, nyní velmi slušně vydělává Nvidia se svými GPU Tesla. A velké množství firem – mezi nimi třeba i Google – pro tyto úlohy vyvíjí speciální akcelerátory, které by se snaží dodat vyšší výkon. Zcela unikátní mezi nimi ale je počin firmy Cerebras, který tak nějak dává nový význam slovům „hrubá síla“ (odtud onen zprofanovaný přívlastek v nadpisu). Cerebras totiž přišlo s technologií, jak vyrobit čip, který je v efektu velký skoro jako celý křemíkový wafer a tím pádem může mít diametrálně vyšší výkon.
Za hranice reticle limitu
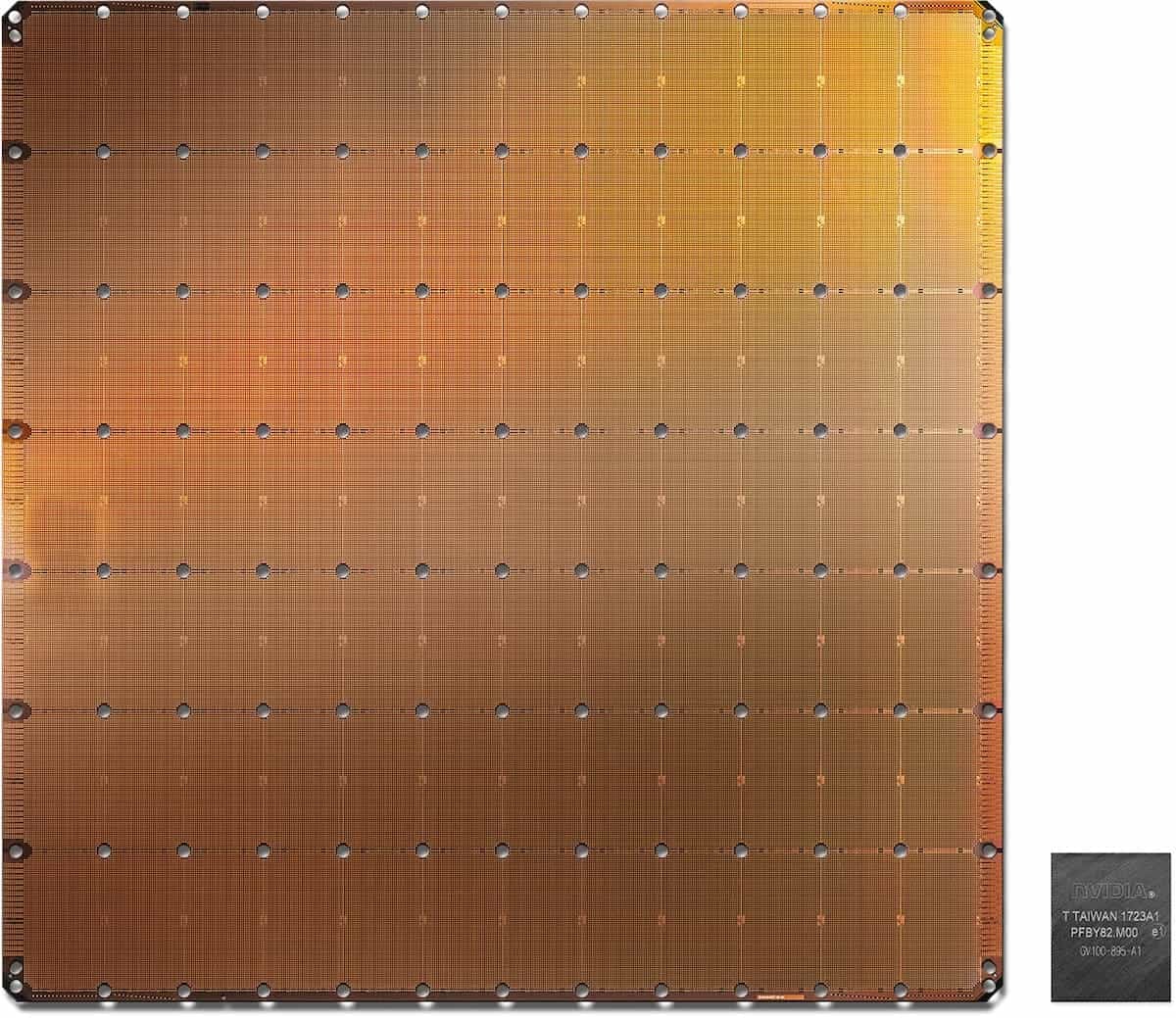
Tato firma nyní svůj AI akcelerátor nazvaný Cerebras WSE („Wafer Scale Engine“) prezentovala na konferenci Hot Chips, ovšem design už byl odhalen i dřív, takže jste o něm už mohli slyšet. Název plus minus pojmenovává, co je cílem: prolomit obvyklé limity velikosti čipů, které jsou historicky někde mezi 600–800 mm². To je dáno tzv. reticle limitem, neboli maximální velikostí, kterou může mít jedna instance čipu. Ta je při výrobě zreplikována po celé ploše waferu, jenž je tvořen křemíkovým kotoučem o průměru 300 mm (ve starších továrnách méně, ale špičková výroba jede dnes na tomto rozměru), který se pak rozřezává na jednotlivé kousky.
Pokud by se ovšem tento limit dal překročit a podařilo se využít celý wafer, mohl by výkon takového řešení být mnohem lepší (samozřejmě i příkon, ale protože by plocha k odvodu tepla byla větší, dala by se uchladit i vysoká spotřeba). Wafer Scale Engine není tak velký projekt, aby si mohl dovolit pokus o to, změnit způsob výroby čipů. Místo toho ale přišel s metodou, jak tyto limity obejít.
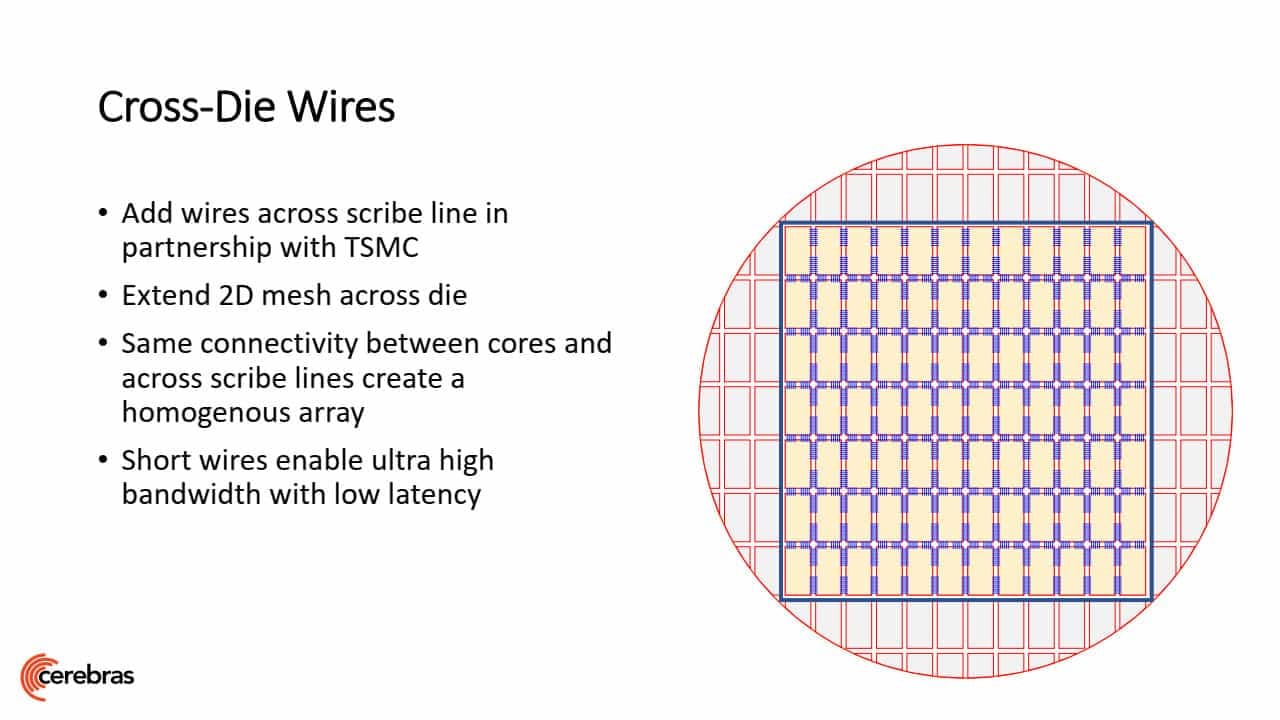
Celý akcelerátor či procesor je vyroben z jedné obdélníkové jednotky, která je na waferu klasicky zreplikována, podle fotek se na wafer vejde blok 7 × 12 těchto bloků. V hotovém procesoru jsou tyto bloky propojené 2D mesh logikou dohromady do jednoho celku. Podmínkou je samozřejmě, že nesmí být třeba nic dalšího (žádné extra „uncore“) mimo tyto bloky.
Naivně by si člověk řekl, že by bylo možné vyvést propojení po okrajích jednoho bloku, aby na ně vedlejší blok rovnou na stejném místě navázal. Ovšem to by při dnešním výrobním postupu nešlo, protože mezi jednotlivými instancemi je ponechán prostor pro následné rozřezávání desky na jednotlivé části, v těchto oblastech se také nachází různé malé bloky pro výrobní testování. A i pokud by tento problém nebyl, dost možná by se nedalo spolehnout, že se opakující se vzor na okrajích vždy přesně strefí a spojí.
Jednotlivé bloky proto nemohou být propojené přímo na waferu, propojení je realizováno vně křemíku, podobně jako jsou propojené jednotlivé čiplety v procesorech Epyc či Threadripper od AMD. Zde ale asi propojení mohou být poměrně krátká, jelikož bloky tohoto superčipu jsou hned u sebe. Není úplně jasné, zda je propojení v substrátu, nebo je o vodiče nanesené po výrobě zvlášť na horní kovovou vrstvu – Cerebras hovoří o „vodičích přemosťující okraje jednotlivých bloků ve spolupráci s TSMC“.
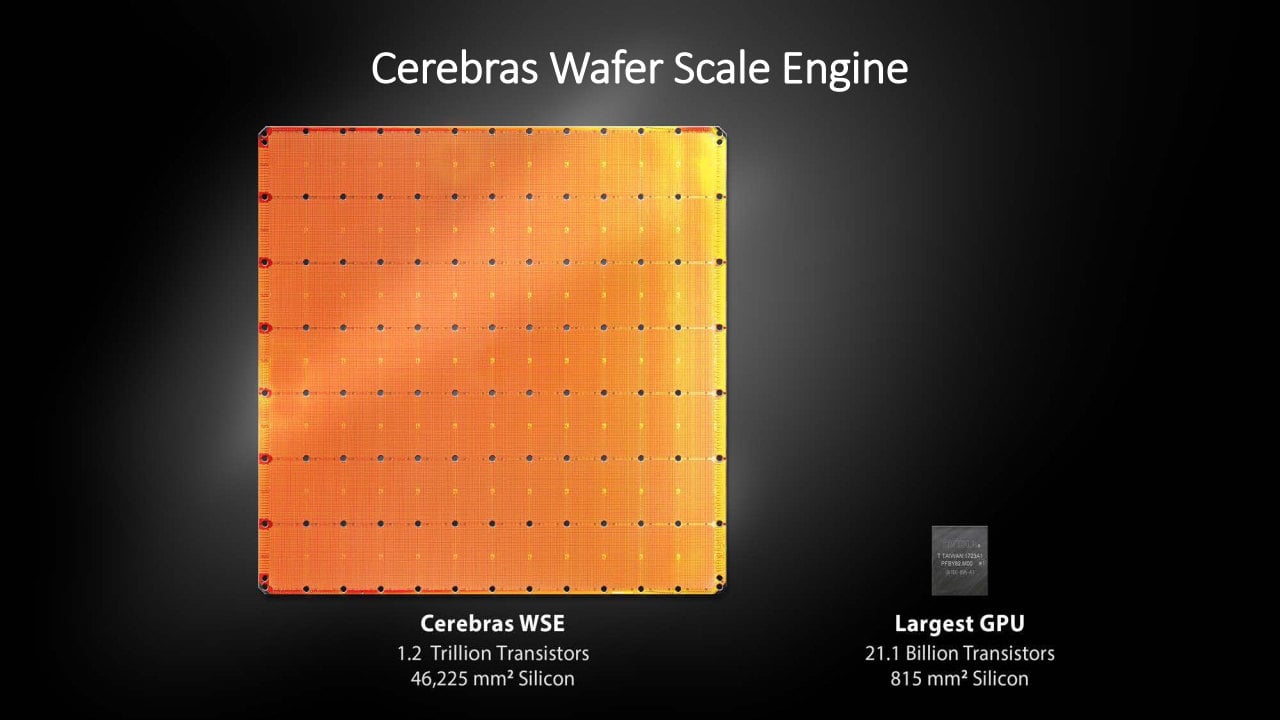
Přes bilion tranzistorů, plocha skoro 5 decimetrů čtverečních
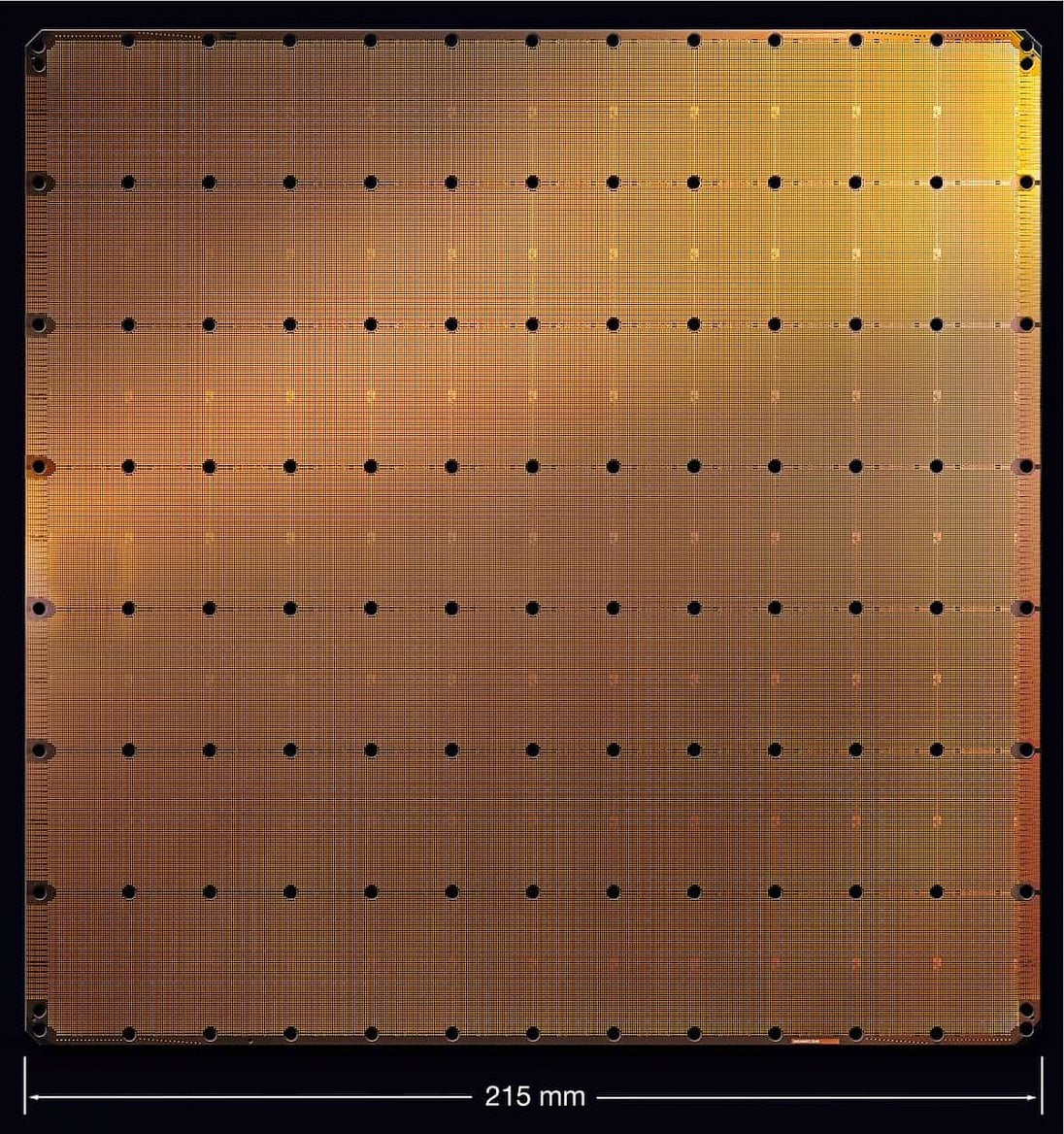
Cerebras WSE používá pro zjednodušení jen obdélníkovou či čtvercovou plochu vepsanou do kruhového waferu, takže nejde o úplně celý 300mm wafer, ovšem celková plocha je 215 × 215 mm (46 225 mm²). Podle autorů obsahuje hotový akcelerátor 1,2 bilionu tranzistorů proti řádově 10–20 miliardám u největších GPU, výroba je přitom na 16nm procesu TSMC s FinFETy. Na této spojené ploše se nachází celkem 400 000 jader a také 18 GB paměti SRAM přímo přítomné v křemíku jako jejich pracovní paměť/cache, její souhrnná propustnost je 9 PB/s (ale to je opět součet nějakých běžných propustností jednotlivých bufferů) a souhrnná propustnost propojení v tomto procesoru má být 100 Pb/s.
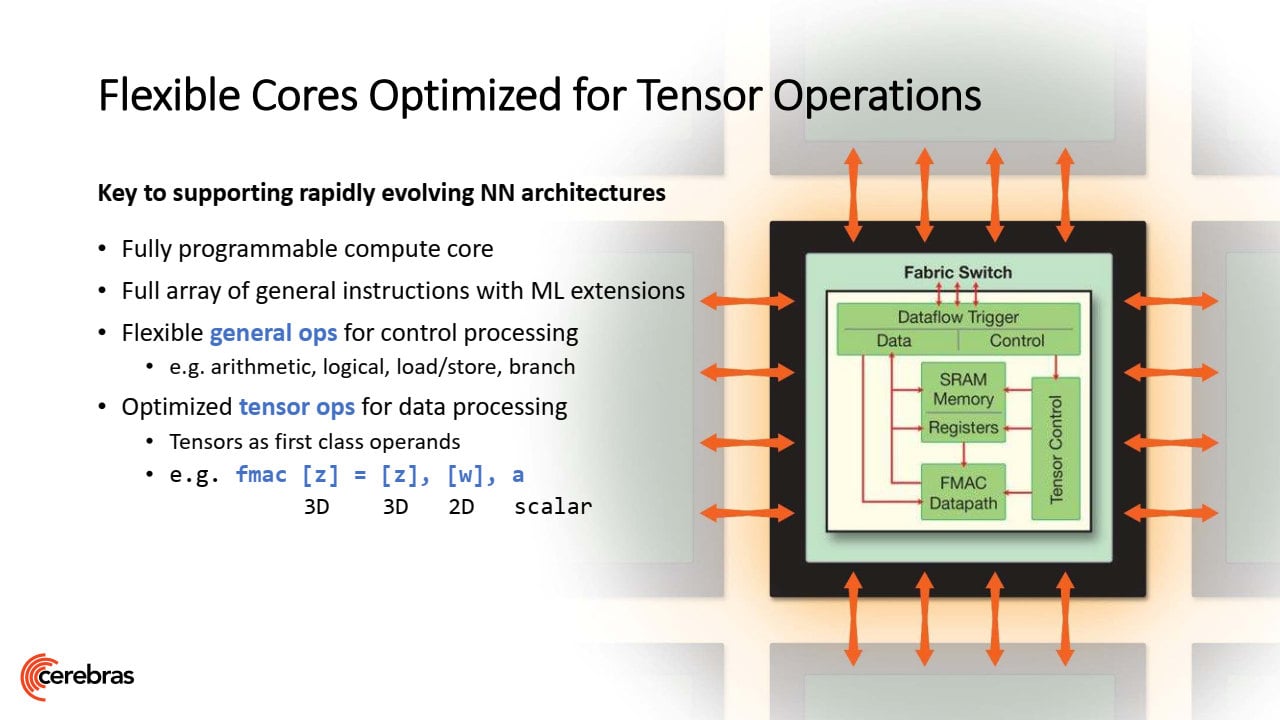
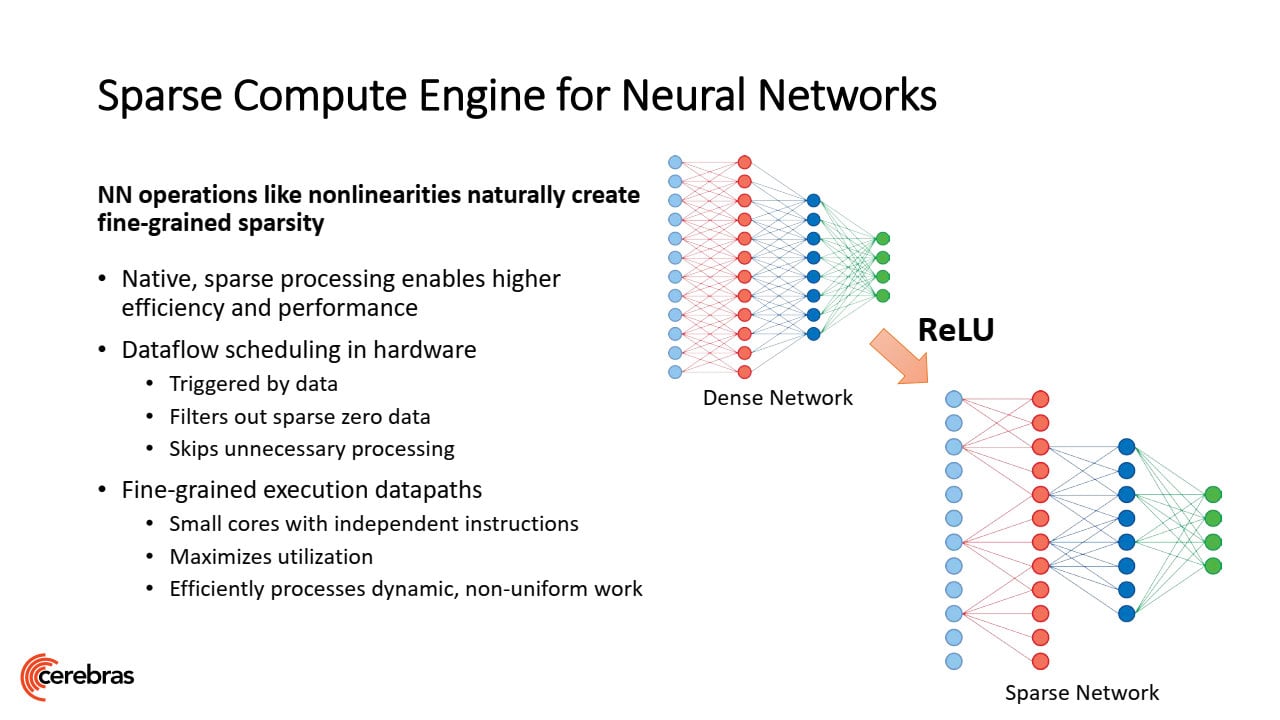
Samotná jádra jsou specializovaná na akceleraci učení neuronové sítě. Tento problém je poměrně náročný na paralelismus, ale má i sériový rozměr, proto ho nelze bezmezně distribuovat například mezi stovku samostatných CPU/GPU a je zde prostor pro takovéto enormně velké procesory, které tím pádem dokáží složitou síť naučit rychleji. Samotné jednotky jader používají tensory a operace FMAC s dataflow schedulingem, využívá se toho, že sítě jsou „sparse“ a přeskakují se výpočty s daty, která mají hodnotu nula, což šetří práci a spotřebu energie. Sítě lzena WSE trénovat pomocí frameworků PyTorch a TensorFlow.
Čip přes celý wafer má unikátní komplikace
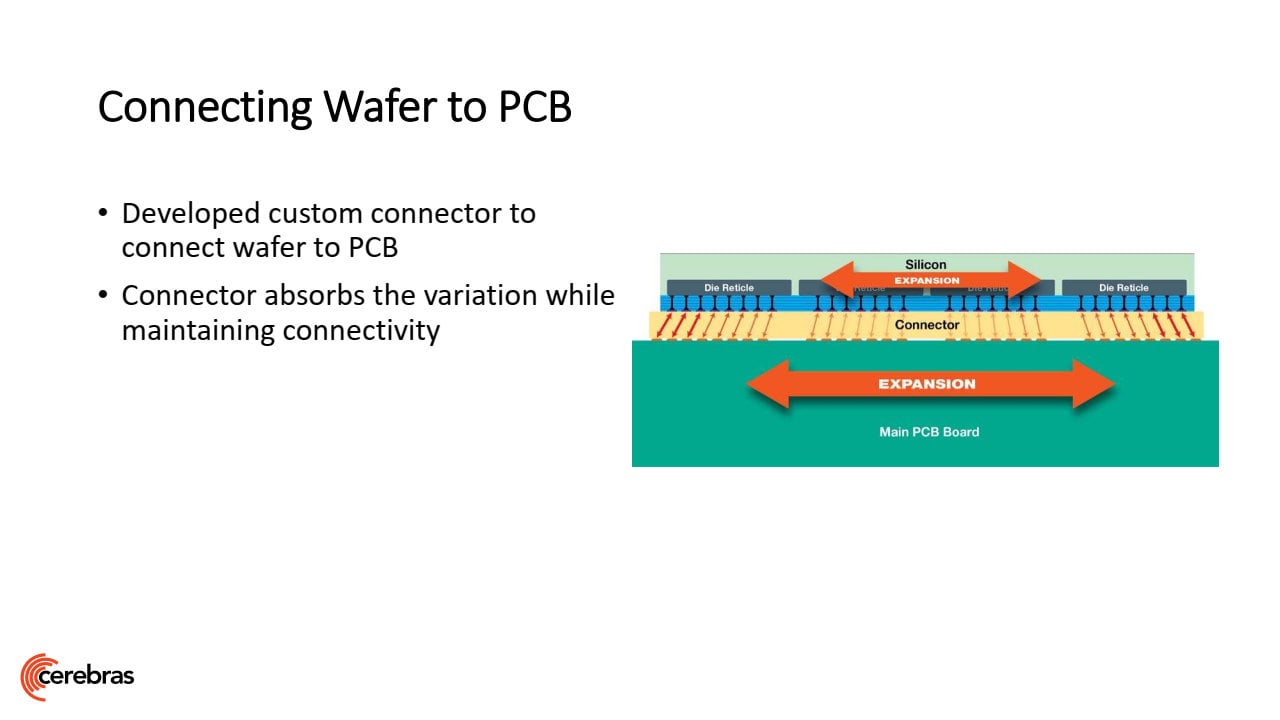
Celý kombinovaný procesor není zas tak snadné realizovat, je to spojené s celou řadou dalších problémů. Jedním je například tepelná roztažnost, kdy samotný křemíkový čip ji má rozdílnou proti substrátu, na kterém je napájený. Protože wafer není rozřezaný, nejsou mezi bloky dilatační spáry. Wafer Scale Engine by se tak choval trochu jako bimetalový pásek a buď by popraskal, nebo by se utrhl. Toto je údajně řešené použitím speciálního materiálu pro napojení na substrát, který by měl pružně kompenzovat odlišné roztažnosti. Samozřejmě je pak velice náročné i přesné osazení velečipu na substrát, k tomu bylo údajně třeba vyvinout speciální přístroje.
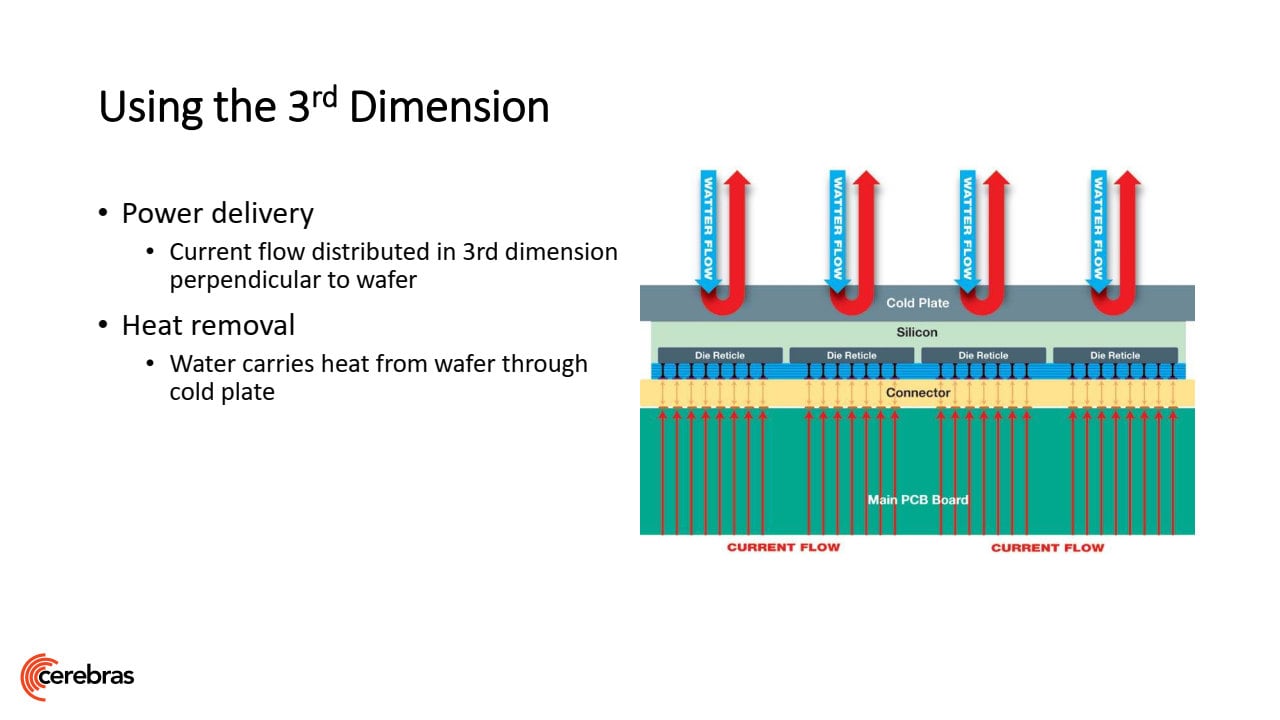
A výzvou je chlazení a napájení, což ukazuje, že Cerebras nemířili na nějaký konzervativní výkon a nízkou spotřebu na jednotku plochy, ale na co nejvyšší rychlostí trénování. Protože pro chlazení a napájení každého centimetru čtverečního není k dispozici větší půdorys chladiče a substrátu, jako je to v případě normálního procesoru, je chlazení vodní. Se vzduchovým by zřejmě nebylo možné WSE provozovat. Voda neobíhá blokem v rovině jako u chladičů pro PC, ale kolmo, tedy jde do něj shora větším množstvím paralelních vtoků, a hned se zase obrací kolmo zpět k výtokům (blok musí vypadat hodně zajímavě). Podobné je to s napájecími vodiči v substrátu – jdou jím kolmo zespodu přímo k jednotlivým částem velečipu.
Zabudovaná redundance se musí vyrovnat s defekty na waferu
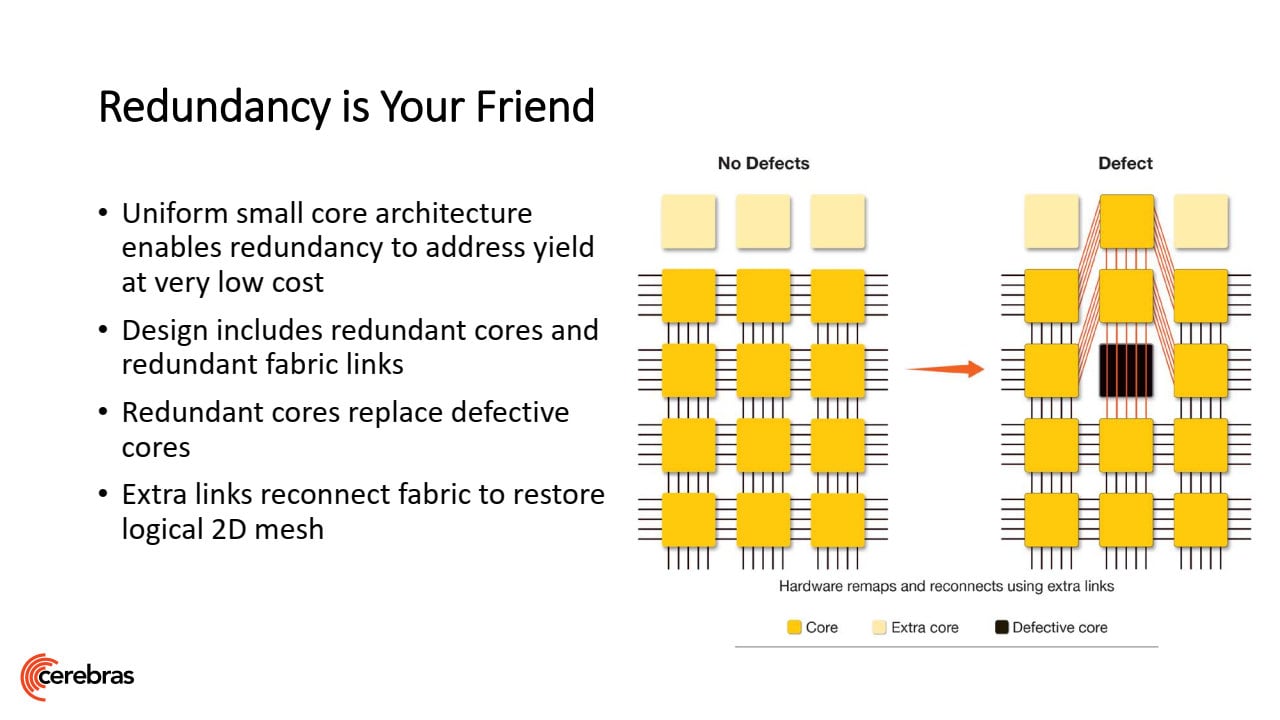
Významným faktorem je také chybovost, které se nelze vyhnout a je prakticky automatické, že na každém waferu nějaké defekty budou (stoprocentně čistý wafer bývá výjimečná věc, pokud se nepletu). To by se normálně řešilo vyhozením postižených kostiček mozaiky, což však Cerebras nemůže. Každý blok je však navržen s vyšším počtem jader, než je třeba, takže defekty se řeší jen deaktivací jádra, na které připadnou. 2D mesh propojení uvnitř bloku lze totiž přeroutovat, takže celková architektura je zachována.

Unikátní, ale drahé řešení
Tento Wafer Scale Engine je dnes opravdu výjimečný kus hardwaru. Bude asi hodně drahý na pořízení, protože jen samotný wafer stojí u TSMC tisíce dolarů a zde je z něj vždy jen jeden procesor (navíc se asi stále někdy při výrobě dojde ke zmetku, kdy je celý wafer odepsán). Ovšem cena zpracování a onoho náročného napájení a chlazení také nebude malá. Nicméně akcelerátor by přesto mohl být hodně žádaný nejmovitějšími klienty. Díky bezkonkurenčnímu množství jednotek, který má agregován do jednoho jediného procesoru, by totiž mohl také povolit bezkonkurenčně rychlé natrénování hodně velké sítě, přičemž za tuto rychlost jsou asi určití zákazníci ochotní zaplatit i nějakou bezkonkurenční cenu (přičemž třeba Google nebo Facebook mohou pak cenu amortizovat aplikací této sítě na velkém množství instancí svých serverů, inference už totiž probíhá na běžném hardwaru).
Podle vyjádření firmy Cerebras je už Wafer Scale Engine v nějaké formě nyní v provozu (zřejmě komerčně), takže nějaké první potvrzení, že nápad funguje, už zde je. Ale samozřejmě až čas ukáže, zda bude tento AI procesor hitem a z Cerebras se stane velké zvíře v AI výpočtech.





