
Z celosvětového boomu umělé inteligence dnes těží převážně Nvidia, kterou prodeje AI GPU katapultovaly během pár let do pozice, kdy má mnohem větší tržby a zisky než jakýkoliv jiná čipová (tzv. fabless v tomto případě) společnost v historii. Řada firem se ale snaží nabídnout konkurenční řešení a AMD se podařilo uchytit s akcelerátory Instinct MI300X. Teď firma vydává novou generaci MI350, která se má Nvidii opět přiblížit.
AMD teď během akce Advancing AI 2025 představilo akcelerátor Instinct MI350, který představuje novou generaci jeho výpočetních GPU. Přestože označení tak trochu implikuje, že jde o menší refresh vůči generaci MI300 s architekturou CNA 3 (což byl případ akcelerátorů Instinct MI325X vydaných loni na podzim), ve skutečnosti má MI350X novou architekturu CDNA 4.
První 3nm GPU
MI350 je současně také první 3nm GPU od AMD (a vlastně vůbec – Nvidia zatím používá 4nm proces), byť určené pro AI aplikace a ne pro grafiku. Jde o akcelerátor složený z čipletů, který má celkově tvořit 185 miliard tranzistorů. Používá 2.5D i 3D pouzdření typu COWOS-S a technologii Hybrid Bonding (jako u V-Cache procesorů).
Hlavní čiplety XCD s výpočetními jednotkami a maticovými jádry CDNA 4 jsou vyrobené 3nm procesem TSMC (technologie N3P) a jsou osazené na základový IO čiplet (IOD), který je vyráběný 6nm procesem (N6).

AMD Instinct MI350
Podle obrázků je celé GPU tvořeno osmi XCD a dvěma IOD, skládá se tedy podobně jako Nvida B200 ze dvou asi relativně samostatných segmentů. Dohromady dávají 256 CU, tedy v tradičním počítání 16 384 shaderů, ale vzhledem k čistě výpočetnímu využití asi nemá smysl o nich takto mluvit.
V pouzdru akcelerátoru je osazená paměť typu HBM3E v celkové kapacitě 288 GB (2× 144 GB), tedy 36 GB v každém z pouzder, která mají celkově 8192bitovou (2× 4096bitovou) sběrnici. Propustnost dosahuje 8 TB/s (či asi 2× 4 TB/s), tedy stejného výkonu jako u GPU Blackwell od Nvidie. To však má jen 192 GB paměti, Kapacita akcelerátorů MI350 je o 50 % vyšší a vejdou se do ní tedy větší (pokročilejší) AI modely.

AMD Instinct MI350
FP6 a FP4 s dvojnásobným výkonem
CDNA 4 přináší důležitou novou schopnost, kterou AMD srovnává krok s architekturou Nvidie – podporu AI výpočtů s přesností FP4 a FP6 (tedy 4bitovými a 6bitovým floating-point čísly). Ta mají velmi zredukovanou přesnost (i když o přesnosti už se asi ani nedá mluvit), nicméně lze je zpracovávat s vyšším výkonem a co je dnes asi hlavně důležité: s menšími datovými typy lze do stejné kapacity paměti, která je dnes zásadním limitujícím faktorem, dostat model s více parametry.
CDNA 4 dokáže zpracovávat operace s hodnotami FP4 s dvojnásobným výkonem proti operacím s hodnotami FP8. Zajímavé je, že stejná rychlost (dvojnásobná proti FP8) je i s větším datovým typem FP6 – jednotky jsou tedy trošku „širší“, zatímco u Blackwellu výpočetní výkon v FP6 padá na úroveň FP8 výpočtů.
AMD nabízí dva modely tohoto akcelerátoru. Výkonnější Instinct MI355X má TDP 1400 W a výkon 20 PFLOPS ve výpočtech s FP4 a FP8, 10 PFLOPS v FP8, 5 PFLOPS v FP16 a ve vědeckých výpočtech s přesností FP64 má dodávat výkon 79 TFLOPS.

AMD Instinct MI350
Vedle toho existuje také model Instinct MI350X, jehož TDP je „jenom“ 1000 W a výkon je o 8 % nižší – 72 TFLOPS v FP64, 18,4 PFLOPS v FP4 a FP6 a tak dále – čísla můžete vidět v tabulce. Nižší ale budou asi jen frekvence výpočetních jednotek tohoto akcelerátoru, takt a propustnost pamětí zůstávají na 8 TB/s.
Tato GPU jsou stavěná na provoz v serverových deskách osazených osmi akcelerátory propojenými pomocí Infinity Fabric. Jako „nosič“ přirozeně mají sloužit procesory AMD a k propojování 400Gb/s adaptéry Ultra Ethernet Pensando Pollara 400 také od AMD). Tato platforma pak poskytuje 2,3 TB paměti HBM3E s celkovou propustnost 64 TB/s a výkon až 161 PF ve výpočtech FP4 a FP6 (nebo 81 PFLOPS v FP8).

AMD Instinct MI350: Výkon konfigurace s 8 GPU
AMD také současně s těmito akcelerátory uvádí novou verzi softwarové platformy ROCm 7, která má také zvyšovat výkon a schopnosti akcelerátorů Instinct.
Lepší výkon než Blackwell?
Podle AMD má akcelerátor být 3,0–3,3× výkonnější v inferenci a 2,6–3,5× výkonnější v trénování proti akcelerátoru MI300X. Proti Nvidia B200 nyní vládnoucímu trhu AI má být výkon 1,0–1,13× vyšší v trénování v FP8 a BFloat16 (toto ale bude asi hodně záležet na softwaru a charakteru zátěže), ale až 1,3× vyšší v FP4 inferenci (v FP6 by mohla být výhoda větší, jak bylo uvedeno). AMD uvádí, že při započítání ceny je MI355X v inferenci podává výkon s až o 40 % více tokeny za jeden dolar.
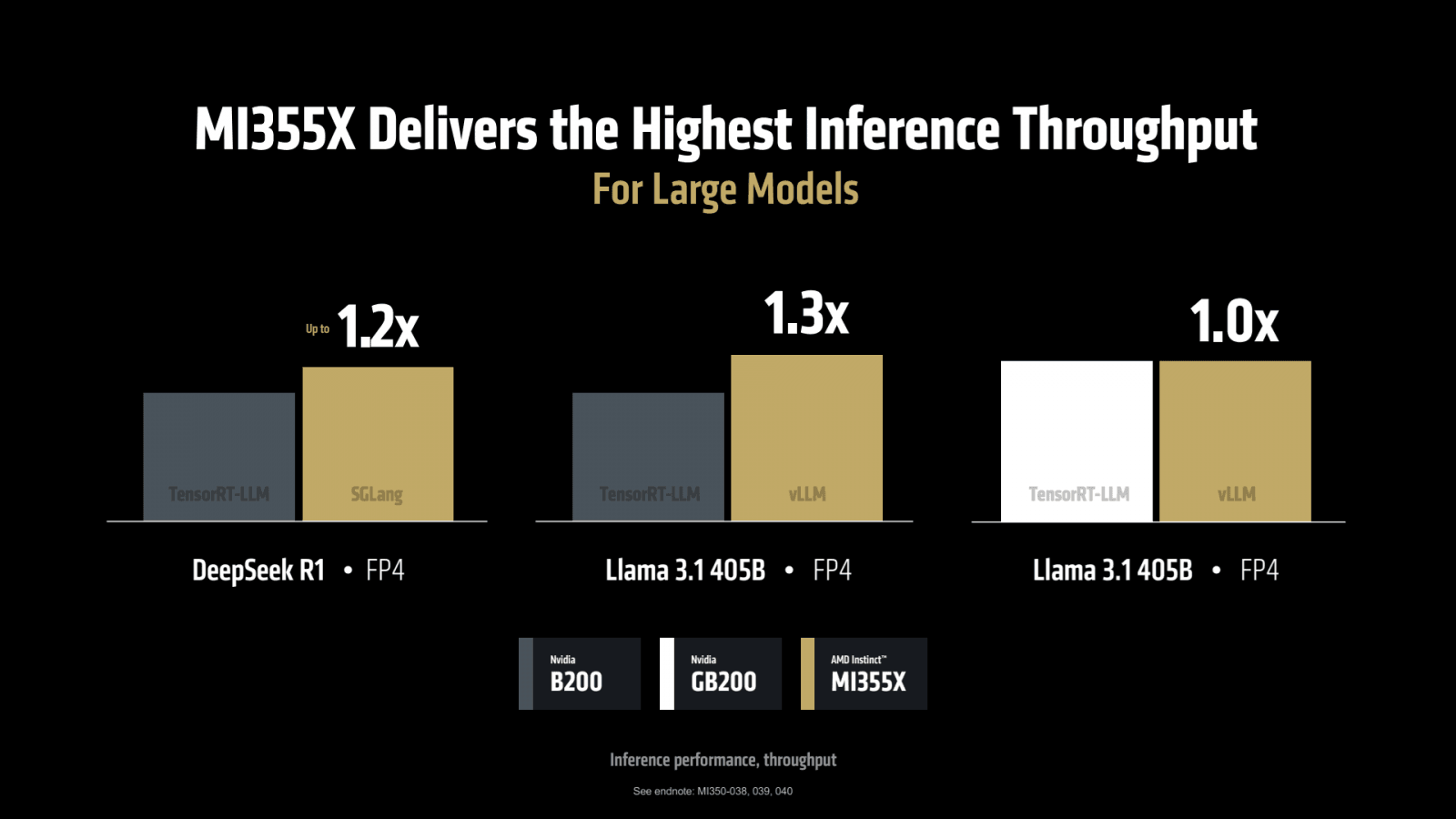
Oficiální benchmarky akcelerátoru Instinct MI355X od AMD
Větší paměť a použití FP4 parametrů může vést k tomu, že v mezních situacích může výkon jít nahoru mnohem více – AMD například tvrdí, že MI355X dodá při inferenci modelu Llama 3.1 405B (se 405 miliardami parametrů) je výkon až 35× vyšší než u MI300X (kde musela být použitá vyšší přesnost FP8). Toto je ale zejména proto, že MI300X nebo jinému staršímu akcelerátoru se model nevejde do paměti, a proto se výkon propadá. Zřejmě by zde MI355X mělo výhodu i proti Nvidia B200 se 192GB pamětí.
Nvidia má ovšem naopak náskok vedle dominantní softwarové platformy také ve větší škálovatelnosti, protože B200 podporuje propojení vyššího množství GPU v racku (až 36 kusů B200) což zase dává větší schopnosti v trénování.

Roadmapa AI akcelerátorů AMD Instinct
Instinct MI400 příští rok
Akcelerátory Instinct MI350X a MI355X budou dostupné ve třetím kvartálu letošního roku. AMD už rovnou oznámilo i novou generaci, která přijde zase už příští rok (2026) – Instinct MI400. Tyto akcelerátory mají dostat 432 GB paměti HBM4, takže opět umožní výrazně větší a tím schopnější AI modely. Její propustnost má už být 19,6 TB/s, tedy skoro 2,5× vyšší.

AMD Instinct MI400
Výpočetní výkon má být až dvojnásobný – 40 PFLOPS v FP4 a 20 PFLOPS v FP8. Navíc zřejmě tyto akcelerátory už budou podporovat propojení do větších rackových systémů s až 72 GPU. Propustnost propojení mezi jednotlivými GPU má být 300 GB/s. AMD tyto akcelerátory plánuje párovat s procesory Epyc Venice s architekturou Zen 6 a 800Gb/s adaptéry Ultra Ethernet (Pensando Vulcano).


MI400 už bude mít novou architekturu, o které se zatím hovoří jako o „CDNA Next“ (CDNA 5?), ale je možné, že už bude místo toho patřit do rodiny UDNA, v které by se měly opět spojit výpočetní architektury CDNA i herní-grafické architektury RDNA. Základ by asi měl pocházet z RDNA 4 / 5, a na něj budou přidány výpočetní a AI schopnosti z linie CDNA.


Zdroje: AMD (1, 2), VideoCardz

