



Highendové GPU Xe HP v socketovém pouzdru
Podobně jako před časem, kdy na Twitteru ukazoval wafer s vyrobenými GPU, stojí za tímto asi opět boss GPU v Intelu Raja Koduri. Sociální účet Intel Graphics publikoval prvního května obrázek čipu – respektive pouzdra opatřeného rozvaděčem tepla. Ten sice vypadá jako procesor (zejména Xeon), ale ve skutečnosti zde bylo ukázáno GPU. Jednak vzhledem k účtu, který tweet publikoval (i s hashtagy, kterými provází všechny tweety o grafickém počínání firmy), dále k tomu, že takto žádné CPU nevypadá a zejména proto, že na tento tweet pak reagoval právě Raja Koduri.
Raja Koduri k fotce přidal, že jde o „baap of all“, což v kombinaci hindštiny a angličtiny zřejmě znamená něco jako „taťka všech“ [míněno asi všech GPU] se zmínkou o výpočtech ve formátu Bfloat, které používají AI akcelerátory.
S tímto se tedy můžete pokochat: na fotkách je poměrně velké pouzdro (můžete si udělat představu podle tužkové baterie na fotce), v němž bude čip/čipy a zřejmě paměti HBM2, obojí nejspíše propojené pamětí EMIB. Napájecí kaskáda se nejspíš nachází vně, na desce okolo speciálního socketu typu LGA, do kterého se pouzdro osadí. Nejde myslím o existující socket (ani LGA 3647, ani LGA 4189 nebo LGA 4677 pro Xeony – i když kontakty jsem nepočítal). GPU by mohlo mít socket vlastní. Kovový IHS sice kryje čip nebo čipy, ale všimněte si SMD součástek na spodku, které tvoří čtyři stejné segmenty. Toto by teoreticky mohlo odpovídat použití čtyři kusů stejného křemíku uvnitř, tedy že by zde šlo o MCM/čipletové GPU podobné koncepci Threadripperů nebo Epyců u AMD. Informace, že by Intel mohl v první generaci GPU použít spojení čtyř čipů, se už objevila dost dávno.
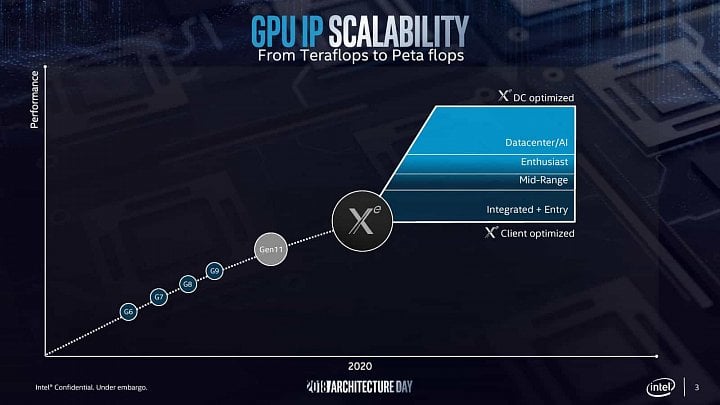
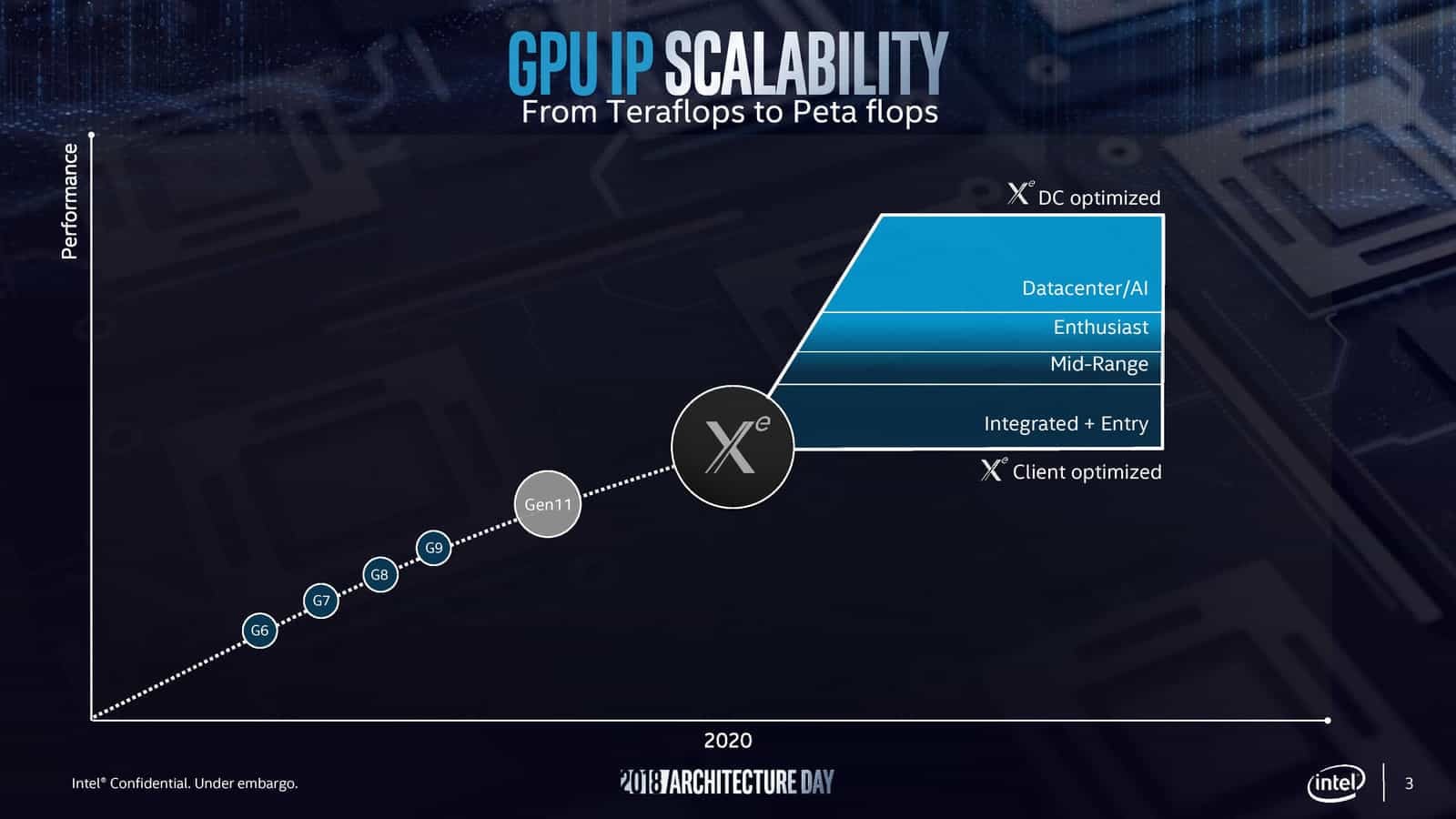
 GPU Intel Xe HP, fotka publikovaná na twitteru Intel Graphics
GPU Intel Xe HP, fotka publikovaná na twitteru Intel GraphicsKoduri prozradil v jiném tweetu, že tímto označením říkají zaměstnanci vývojového centra Xe HP v Bangalore čipu, jenž „je zřejmě největším křemíkem, který kdy byl navržen na území Indie a patří k těm největším vůbec“. Opět je zde tedy zmínka o Xe, čili GPU.
https://twitter.com/Rajaontheedge/status/1202393950771744768
Pokud jde o jeden z největších křemíků vůbec, pak se zřejmě pohybujeme někde mezi 600–800 mm². A pokud jsou tyto použité čtyři, pak může výsledek mít dohromady kolem 3000 mm², což by muselo dodávat velmi vysoký výkon. Samozřejmě s ohledem na limitaci spotřebou. I při 400–500W TDP by na jeden takto velký čip připadalo jen omezujících 100–125 W. Je ale možná i interpretace, že oněch 600–800 je souhrnná velikost všech čtyř čipů. Je pravda, že circa 100 až 125 W na zhruba 200mm² čiplet asi dává větší smysl, ale zase nechceme Intel podcenit.
Viz: Grafické karty Intel Xe „Arctic Sound“: Až 4096 shaderů, HBM2 a PCIe 4.0, TDP až 500 W
Druhá varianta by mohla sedět k tomu, že Xe HP bude mít 128 čili 1024 shaderů na jeden čiplet (celkem 4096), jak se dříve spekulovalo. Pokud by samotný jeden čiplet měl onu obří velikost, pak by seděla spíš optimistická alternativní interpretace, že 4096 shaderů obsahuje ve skutečnosti jediný čiplet, takže pro celé čtyřčipové monstrum je to 16 384). Uvidíme, co z tohoto se potvrdí.
Na trh by se toto GPU mělo dostat ještě letos, takže moc dlouho už snad záhadou nezůstane. Jde ale zřejmě o produkt čistě pro servery, ne o herní GPU. Intel by na stejném křemíku (třeba s použitím jednoho čipletu místo čtyř) ale mohl nějaké klientské a potenciálně herní grafiky vydat, úniky tuto možnost i zmiňují, jen ale asi budou vypadat jinak.
https://twitter.com/Rajaontheedge/status/1256849904263024641
Intel se prý zpočátku soustředí na integrované a levnější GPU
Koduri také nyní zatweetoval, že se Intel momentálně soustředí na integrované GPU (Xe v procesorech Tiger Lake bude mít 96 EU/768 shaderů) a na samostatné grafiky ve výkonnostních segmentech hned nad integrovanými.
https://twitter.com/Rajaontheedge/status/1256849910617370624
To by mohlo sedět k oněm 128 EU/1024 shaderům, o nichž se už jednou objevila informace dříve. Ale zatím není potvrzené, zda spotřebitelské GPU Intel Xe a datacentrové GPU Xe HP byly založené na stejných čipletech, takže není jasné, zda na tomto můžeme zakládat nějaké úvahy.
Tipněte si: kolik bude mít špičkové serverové GPU Intel Xe HP mít EU/shaderů?
Speciální provedení místo karty PCIe může mít strategický význam
To, že je GPU Xe HP v provedení do proprietárního socketu, má technologické nevýhody i výhody. Nelze ho instalovat bez toho, aby na to deska byla speciálně připravená (ovšem je možné, že verzi do slotu má Intel také vyvinutou), ale zase se může usnadnit chlazení. Tato proprietární řešení, jaké má také Nvidia v podobě modulů SXM, v nichž vyrábí GPU Tesla, jsou pro výrobce zajímavé ale i tím, že fungují jako háček na zákazníky. Pokud jednou prodáte desku nebo server, který je stavěn na takováto GPU, nebude provozovatel moci vaši produkci nahradit za konkurenční GPU nebo jiný akcelerátor, ať už ASIC pro neuronové sítě, FPGA nebo jiný. A podobně, pokud přesvědčíte OEM výrobce k tomu, aby server založili na této technologie a místo slotů PCIe do něj přichystali sloty/sockety pro podobná speciální provedení grafik, máte tím zase zajištěné to, že zákazníci budou muset nakupovat vaše GPU. Což pak znamená možnost vyšších cen díky eliminaci konkurence.

Intelu se takto může podařit prosadit vlastní GPU a poměrně rychle dostat významné tržní podíly, ačkoliv začíná jako outsider v sektoru, kde by normálně mělo být obtížné se prosadit proti zavedené konkurenci. Ale Intel má velkou schopnost určovat chování trhu skrze dominanci serverových CPU Xeon. To ukázala třeba situace, kdy konkurenční procesory AMD Epyc vzdor vyšší energetické efektivitě a výkonu nezískávají výrazné prodeje a trh jako by se jim skoro bránil, ačkoliv by tyto vlastnosti dle dřívějších pozorování měly být rozhodující. Pokud by se Intelu podařilo dosáhnout pomocí bundlů nebo jiných pobídek, aby toto provedení akcelerátorů bylo použito u důležitých serverů velkých výrobců, dokázal by prosadit svoje řešení GPU pomocí tohoto spojení a uchytit se na důležitém novém trhu.
Zdroje: Intel/Twitter (1, 2, 3, 4), VideoCardz