Když vám dnes někdo pošle obrázek údajného výbuchu, zatčeného politika nebo nového telefonu, stará rada „podívejte se na ruce“ už moc nefunguje. Generátory se zlepšily. Text na cedulích není takový cirkus jako dřív, obličeje bývají přesvědčivé a při rychlém prohlížení si člověk spíš všimne celkového dojmu než drobností v oku nebo na ruce.
Na Cnews jsme to viděli už u fotorealistických obrázků z ChatGPT. Podobné obrázky dnes nevznikají jen v nástrojích OpenAI. Zvládne je Zoner AI, cloudové služby od Googlu nebo lokální modely typu Stable Diffusion, které si můžete rozběhnout i na vlastním počítači, jak jsme popisovali u offline AI nástrojů. Hádat podle artefaktů už nestačí. U podezřelého souboru chcete vědět, jestli má dohledatelný původ.
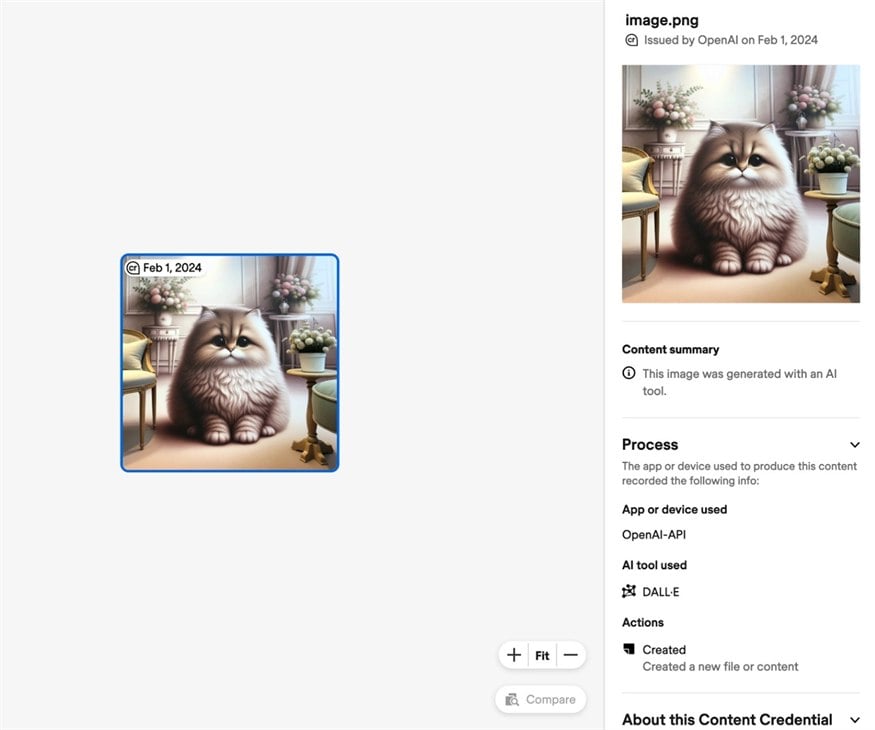
Content Credentials jsou rodný list souboru
Nejznámější odpovědí je standard C2PA a nad ním postavené Content Credentials. Do souboru se přidá podepsaný záznam o tom, kde vznikl, jakým nástrojem prošel a zda při tvorbě nebo úpravě hrála roli AI. Oproti běžnému EXIF má jednu výhodu: editor ho nemůže jen tak přepsat bez následků. C2PA používá kryptografické podpisy a otisk obsahu, takže ověřovač pozná, že někdo po podpisu změnil data nebo samotný obraz.
Představte si to jako rodný list a servisní knížku v jednom. U fotky z podporovaného fotoaparátu může být vidět, že ji pořídila kamera. U obrázku z generátoru může být vidět, že vznikl v AI nástroji. U editace může záznam ukázat, že někdo soubor otevřel ve Photoshopu nebo Google Fotkách a provedl úpravu. Kolik detailů uvidíte, záleží na konkrétním nástroji, nastavení a na tom, co po cestě zachovaly weby a aplikace.
OpenAI dnes u obrázků vytvořených přes ChatGPT a API uvádí kombinaci C2PA metadat a SynthID vodoznaku. Google zase rozšiřuje C2PA a SynthID v Gemini, Vyhledávání, Chromu a Pixelech. Podle Googlu byl Pixel 10 prvním smartphonem s Content Credentials přímo ve výchozí aplikaci fotoaparátu a ověřování se má rozšířit i na video u Pixelů 8, 9 a 10.
Ověřovací nástroj neříká, zda je scéna pravdivá. Ukazuje jen dostupný původ a historii souboru.
Vodoznak přežije víc úprav, ale nese méně informací
Metadata a vodoznak se často hází do jednoho pytle, jenže fungují jinak. Metadata jsou uložená vedle samotného obrazu. Mohou nést bohatší popis: nástroj, podpis, historii úprav, někdy i informaci o zařízení. Jejich slabina se ukáže při sdílení na internetu. Stačí změna formátu, export, zmenšení, agresivní komprese nebo nahrání na službu, která metadata zahodí.
Vodoznak typu SynthID se vkládá přímo do obrazu. Člověk ho nevidí, ale ověřovací nástroj ho může najít i po některých úpravách. Google uvádí odolnost proti ořezu, filtrům nebo ztrátové kompresi. OpenAI píše, že vodoznak může přežít i situace, kde metadata zmizí, třeba screenshot. Jenže slovíčko „může“ je tady podstatné. Neviditelný vodoznak není fyzikální zákon. Při silném překreslení, opakovaném sdílení nebo špatném screenshotu může zeslábnout nebo zmizet.
Z toho plyne jednoduchý závěr: metadata řeknou víc, vodoznak má větší šanci přežít běžnou nešetrnost sociálních sítí. Kombinace metadat a vodoznaku je lepší než jeden prvek samotný. Důkaz z obrázku ale neudělá ani tahle dvojice.
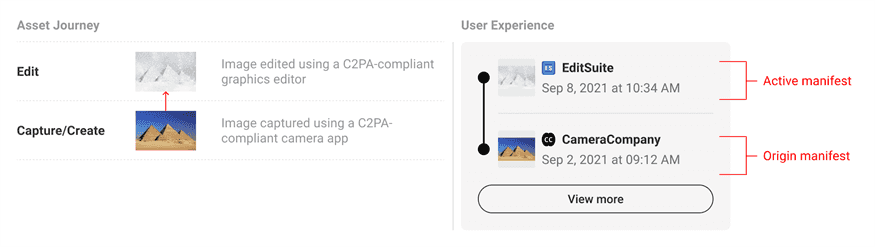
Content Credentials ukazují cestu souboru od pořízení nebo vytvoření po pozdější úpravy. Neříkají ale, zda je tvrzení kolem obrázku pravdivé.
Podepsaný obrázek může pořád lhát kontextem
Nejčastější omyl začíná u záměny původu a pravdivosti. Content Credentials ani SynthID neověřují pravdivost scény. Ověřují původ nebo historii souboru, pokud se k nim zachovala použitelná metadata nebo značka. C2PA to ve vlastním explaineru říká přímo: údaje o původu samy nerozhodují, zda je digitální obsah pravdivý, přesný nebo faktický.
OpenAI u svého ověřovače používá podobně opatrnou formulaci. Nástroj může potvrdit, že obrázek pochází z nástrojů OpenAI. Nepotvrzuje ale přesnost obrázku, to, zda nebyl dál upravený, právní vlastnictví ani správný kontext. Tuhle větu by si sociální sítě mohly lepit vedle každého štítku „AI“.
Proč na tom záleží? Fotka může být technicky pravá a stejně zavádějící. Může ukazovat naaranžovanou scénu, starou událost vydávanou za novou, výřez bez okolí nebo snímek z jiného města. AI obrázek zase může být poctivě označený jako vygenerovaný, ale někdo ho přepošle se smyšleným popiskem. Digitální původ řeší soubor. Nepravda bývá často až v textu kolem něj.
Screenshot ověřování výrazně komplikuje
Při běžném sdílení se navíc málokdy šíří původní soubor. V rodinném chatu přistane screenshot příspěvku. Na X vidíte přefocený obrázek z Telegramu. Na Facebooku koluje koláž, kterou už někdo třikrát zmenšil a jednou přidal do videa. Každý takový krok zhoršuje šanci zjistit původ.
Screenshot je pro ověřování zvlášť problematický. Zahodí původní metadata, změní rozlišení a místo souboru ověřujete jen pixely z obrazovky. Pokud měl původní obrázek C2PA manifest, do screenshotu se běžně nepřenese. Některé vodoznaky mohou přežít, ale nespoléhal bych na to u obrázku, který prošel přes několik aplikací a kompresí.
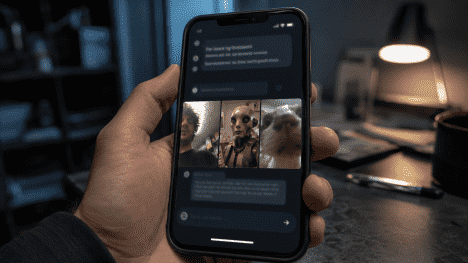
Navíc screenshot psychologicky klame. Vidíte jméno účtu, čas, počet lajků a kus rozhraní. Vypadá to jako důkaz původu, ve skutečnosti je to další obrázek, který lze vyrobit nebo upravit. U podvodných virálů se často nešíří samotná „fotka události“, ale screenshot údajného příspěvku. To není lepší důkaz, spíše jen další překážka na cestě k původnímu souboru.
Když ověřovač mlčí, neznamená to automaticky podvod
Stejně nebezpečný je opačný závěr. Nahrajete obrázek do ověřovače, nic se nenajde, hotovo, je falešný. Takhle se k tomu přistupovat nedá. Velká část legitimních fotek v oběhu žádné Content Credentials nemá. Starší telefony je nepřidávaly, mnoho aplikací s nimi neumí pracovat a řada webů metadata při nahrání odstraňuje.
Platí to i pro AI. OpenAI, Google, Adobe nebo Meta mohou přidávat vlastní značky, ale generátorů je mnohem víc. Některé běží lokálně, některé jsou postavené na open-source modelech, některé metadata nepřidají vůbec. Pokud ověřovač nic nenajde, dá se z toho říct jen jedno: v tomto souboru se nenašla podporovaná značka ani metadata. Víc z toho nevymáčknete.
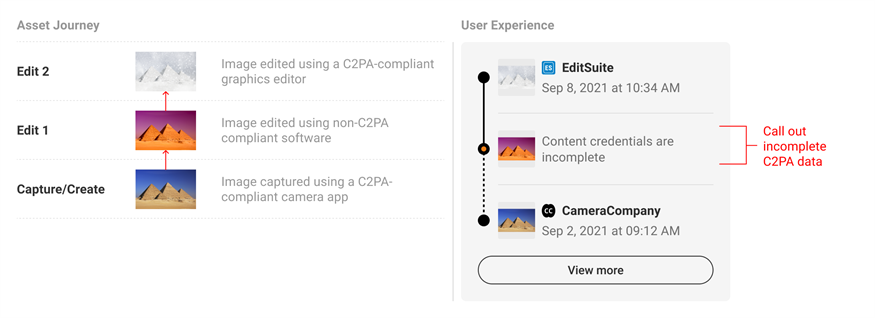
Neúplná historie není totéž co důkaz podvodu. Znamená jen, že část cesty souboru se nepodařilo ověřit.
Ostatně i platformy s označováním AI obsahu pracují opatrněji, než jak to vypadá z tiskových zpráv. Meta už v roce 2024 psala, že chce na Facebooku, Instagramu a Threads číst C2PA a IPTC značky od dalších firem, ale zároveň přiznávala limity. Technické značky jde odstranit a ne každý typ obsahu se označuje stejně snadno.
Rozumný postup začíná u původního souboru
Co tedy dělat, když vám přistane podezřelý obrázek? Často rozhodne hned první krok: zkuste se dostat k originálu. Ne ke screenshotu, ne k přeposlanému náhledu, ne k obrázku vloženému do videa. Otevřete původní příspěvek, stáhněte soubor z prvního známého zdroje nebo požádejte o původní fotku.
Pak mají smysl ověřovače. Content Credentials Verify ukáže C2PA data, pokud v souboru jsou. OpenAI má vlastní ověřovač pro obrázky z jeho nástrojů. Gemini umí u podporovaného obsahu hledat SynthID. Když nástroj najde původ z AI generátoru, je to užitečná informace. Když ho nenajde, znamená to jen, že soubor neposkytl podporovaný údaj.
Pak přichází na řadu běžné ověřování: reverzní vyhledávání obrázků, hledání nejstaršího výskytu, kontrola účtu, porovnání místa s mapami, počasím, nápisy, SPZ nebo architekturou. U citlivých fotek obličejů přidejte ještě větší zdrženlivost. Už u tématu nahrávání fotek do AI služeb jsme řešili, že kvalitní snímek člověka se dá zneužít pro deepfake nebo podvod.

Nejlepší otázka nezní „je to AI?“. Lepší je rozebrat tvrzení na menší kusy. Tvrdí autor, že se něco stalo dnes? V konkrétním městě? Konkrétní osobě? Před určitým obchodem? Za určitého počasí? Každý kus se ověřuje jinak. Obrázek sám je jen jedna část, často ještě ta nejméně průkazná.
Štítky pomohou hlavně slušným autorům
Digitální původ má smysl. Pro redakce, fotobanky, úřady, pojišťovny nebo soudní spory může podepsaný soubor ušetřit hodně času. Pro běžného uživatele je užitečný jako rychlá nápověda: tenhle soubor pochází z AI nástroje, tenhle prošel editorem, tenhle má ověřitelný záznam z fotoaparátu.

Jenže nejvíc pomáhá tam, kde se někdo nechce schovávat. Fotograf, redakce nebo firma může původ doložit. Podvodník může vzít screenshot, přegenerovat obrázek, přepsat popisek nebo použít nástroj, který nepřidá žádná metadata ani vodoznak. Na druhé straně by byla chyba kvůli tomu celé značení odepsat. Bez něj by uživatel neměl ani tu první stopu.
Berme tedy Content Credentials, C2PA a vodoznaky jako užitečnou pomůcku, ne jako soudce. Když něco najdou, stojí za to podívat se na podrobnosti. Když nic nenajdou, práce teprve začíná. A pokud obrázek nese silné tvrzení o válce, politice, zdraví nebo konkrétním člověku, nejrozumnější reakce je pořád stejná: nesdílet hned, hledat původ a ptát se, co přesně má obrázek dokazovat.

