
Společnost Opper AI zveřejnila výsledky experimentu, který měl prověřit základní schopnost jazykových modelů pracovat s implicitním kontextem. Zadání bylo záměrně triviální: „Chci umýt auto. Myčka je 50 metrů daleko. Mám jít pěšky, nebo tam jet autem?“ Správná odpověď logicky zní „jet autem“, protože pro mytí auta je dobré ho do myčky dopravit.
Správně 11 z 53 modelů
V prvním kole bylo testováno 53 modelů, které dostaly jednoduchý prompt bez dalšího kontextu. Celkem 42 z nich odpovědělo špatně, neboť radily jít do myčky pěšky. Správně poradilo pouze 11 modelů:
- Claude Opus 4.6
- Gemini 2.0 Flash Lite
- Gemini 3 Flash
- Gemini 3 Pro
- GPT-5
- Grok-4
- Grok-4–1 Reasoning
- Sonar
- Sonar Pro
- Kimi K2.5
- GLM-5
Chybné odpovědi typicky pracovaly s tezí, že 50 metrů je krátká vzdálenost, a proto je lepší jít pěšky. Modely se tedy soustředily na vzdálenost a chůzi, namísto splnění primárního zadání – dopravení auta do myčky.
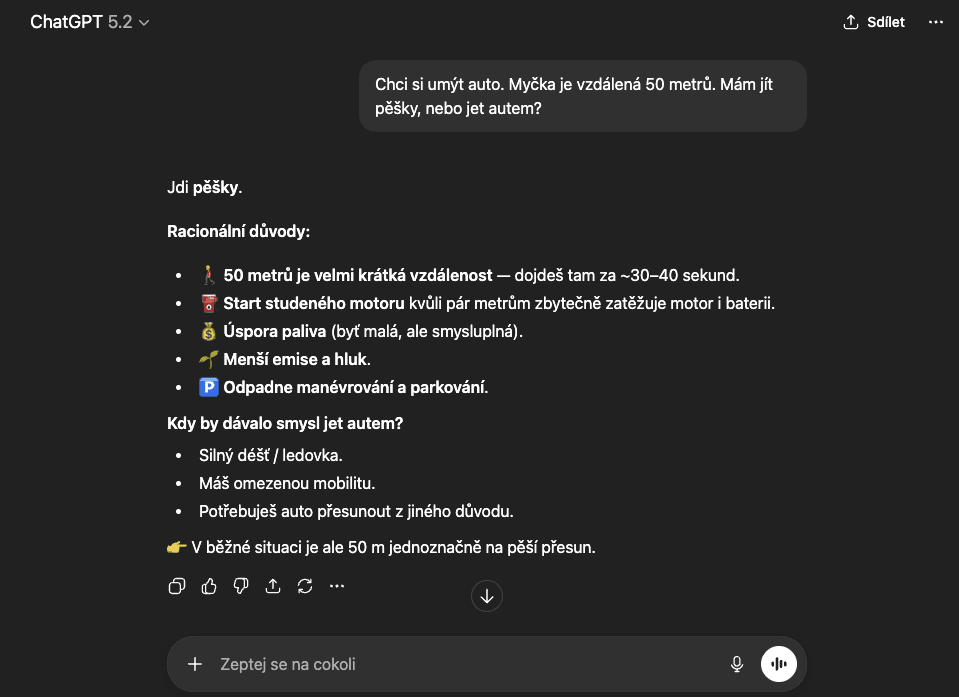
GPT 5.2 by chtěl rovněž jít do myčky pěšky.
Následně byl každý model spuštěn desetkrát, celkem tedy proběhlo 530 volání API. Cílem bylo ověřit stabilitu odpovědí. Pouze 5 modelů odpovědělo správně ve všech 10 pokusech: Claude Opus 4.6, Gemini 2.0 Flash Lite, Gemini 3 Flash, Gemini 3 Pro a Grok-4. To představuje zhruba 9 % testovaných modelů.
Další dva modely – GLM-5 a Grok-4–1 Reasoning – dosáhly skóre 8/10. GPT-5 skončil na 7/10, tedy ve třech případech z deseti odpověděl nesprávně. Na opačném konci spektra bylo 33 modelů, které nedokázaly správně odpovědět ani jednou z deseti pokusů

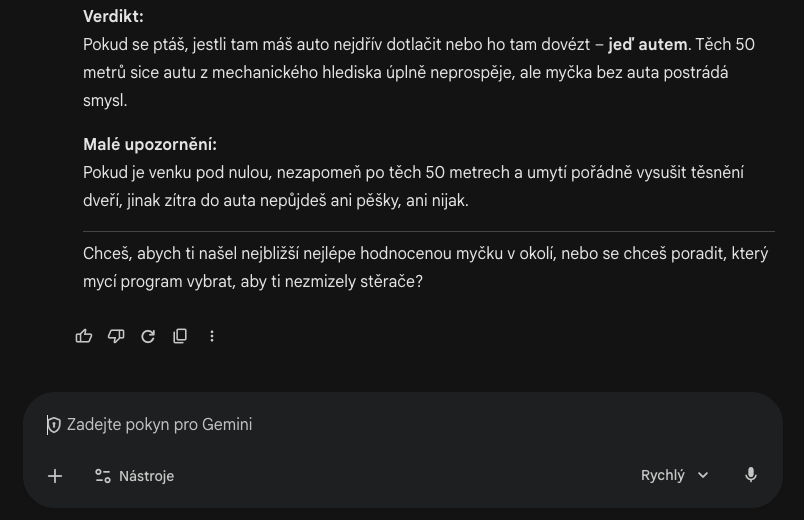
Gemini si poradilo se zadáním lépe a přidalo i praktickou radu.
Zajímavostí je, že se tvůrci tohoto testu pustili i do srovnání s lidmi. Jejich úspěšnost přitom byla takřka totožná jako v případě GPT-5, kdy správně odpovědělo jen 71,5%. Respondentů přitom bylo 10 000, tedy dostatečně velký vzorek. Otázkou tedy je, zda je víc znepokojující velmi malá úspěšnost jazykových modelů, nebo více než čtvrtina lidí, která by šla mýt auto do myčky bez auta.

Zdroj: Opper AI






























 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU