
Nová GPU generace Blackwell / RTX 5000
GPU generace RTX 5000 / Blackwell jsou celkově nová architektura proti předchozí generaci 4000 s architekturou Ada Lovelace. Prakticky všechny součásti by měly být změněné či aktualizované na novější verzi IP. S jednou výjimkou – GPU jsou stále vyráběná stejným procesem jako GPU architektury Ada Lovelace: technologií 4N od TSMC, což je pro Nvidii speciálně upravená verze procesu N5. Toto je rozdíl proti výpočetní verzi Blackwellu (akcelerátor B200/GB200) pro servery, kde Nvidia použila proces nazvaný 4NP s nějakým dalšími laděním navíc.
GB202
Nejvýkonnější čip v generaci Blackwell, GB202 s 92,2 miliardy tranzistorů, má mít plochu 750 mm², obsahuje 192 bloků SM (SM = Streaming Multiprocessor), což dává 24 576 shaderů. SM jsou rozložené v 96 blocích TPC (Texture Processing Cluster) po dvou SM. V jednom bloku SM jsou nadále přítomná RT jádra (jedno na SM) a tensor jádra (čtyři na jeden SM). GB202 má tedy 192 RT jader a 768 tensor jader.
Na úrovni bloků TPC se vedle dvou SM nacházejí také texturovací jednotky v počtu osmi – GPU jich tedy má 768. V reálně prodávaných konfiguracích bude část vypnutá, počty jednotek závisí na počtu aktivních TPC.
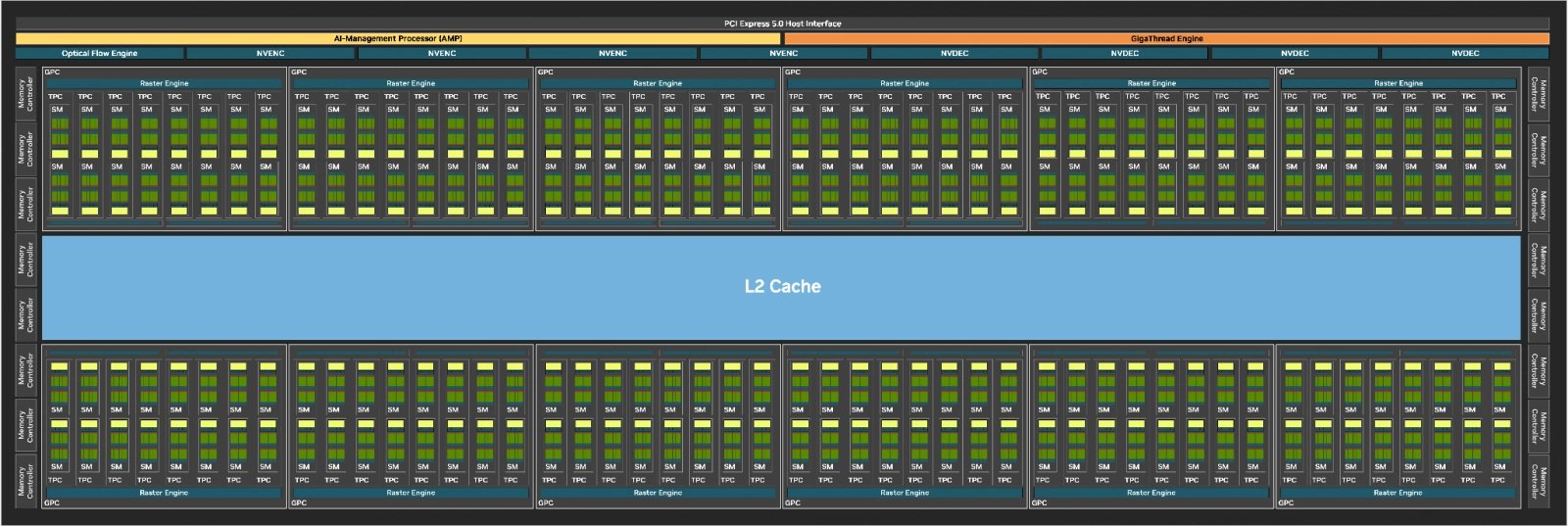
Schéma GPU Nvidia GB202
TPC jsou zase spojené do 12 bloků GPC (Graphics Processing Cluster), kdy jeden GPC obsahuje 8 TPC (a tím 16 SM). Na úrovni GPC by měly být přítomné jednotky ROP v počtu 16 na jeden blok GPC (dvě Raster Operation Partitions po 8 ROP). Celé GPU GB202 obsahuje 192 ROP, při vypnutí bloku GPC ale grafika o jeho jednotky přijde, takže například RTX 5090 by měla mít jen 176 ROP (má totiž 11 aktivních GPC, 170 SM).
GDDR7
GPU generace Blackwell jsou první, které používají paměti GDDR7. V případě čipu GB202 je to dokonce s 512bitovou paměťovou sběrnicí (poprvé od generace Fermi). Řadiče jsou stále 32bitové, v GB202 je jich tedy paralelně 16 (a odpovídající počet v nižších GPU). V GeForce RTX 5090 s čipem GB202 jede GDDR7 na efektivním taktu 28,0 GHz a podobné to asi bude u většiny modelů. RTX 5080 však pro paměti používá efektivní takt 30,0 GHz.
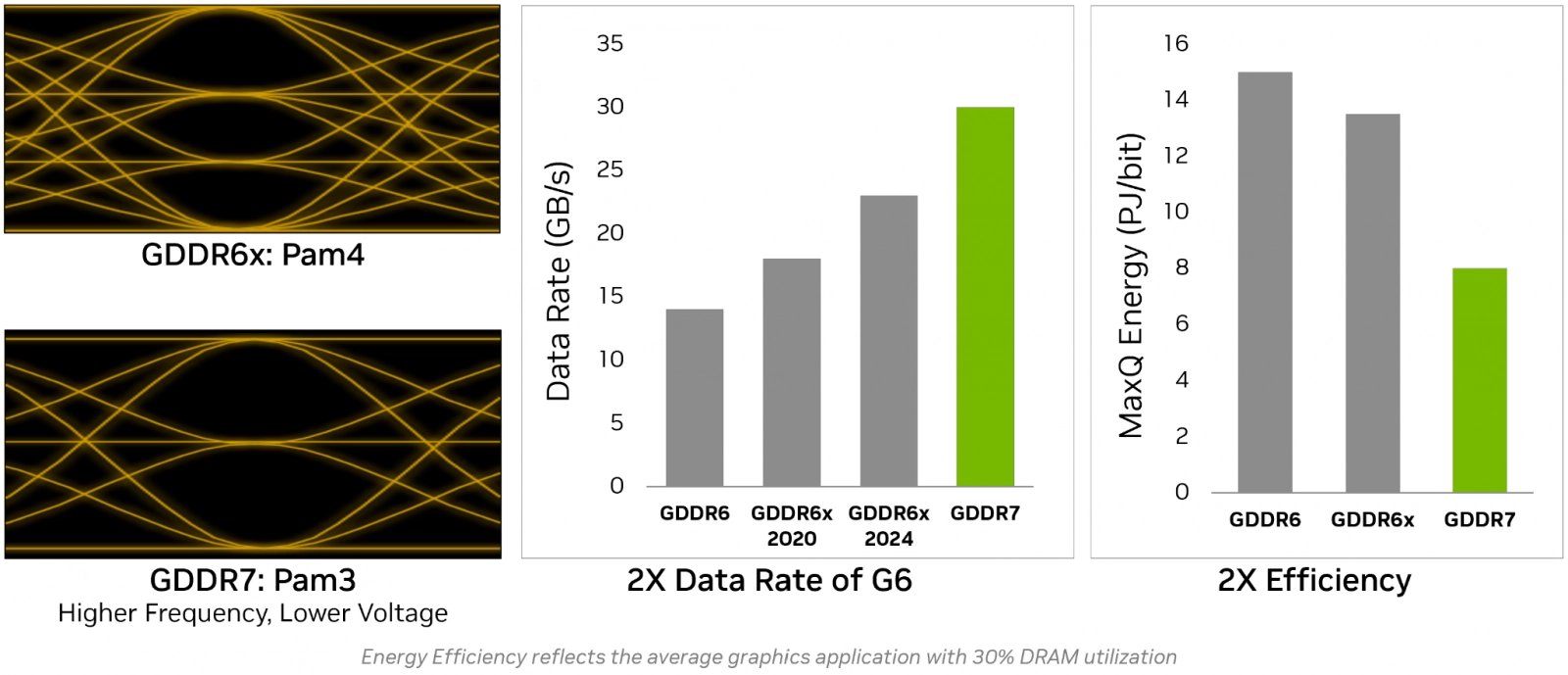
GDDR7 v GPU Blackwell
GDDR7 používá pulzně amplitudovou signalizaci PAM3, která přenese 1,5 bitu za cyklus. To na první pohled může působit jako krok zpět proti PAM4 (2 bity za cyklus) použité u GDDR6X, ale zdá se, že jednodušší signalizace spolu s možná více vyladěnou technologií dovolují, aby komunikace GDDR7 měla při stejném taktu výrazně lepší odstup signálu od šumu, takže sice přenese o 25 % dat méně za jeden cyklus, ale může se nataktovat mnohem výše, takže finální „efektivní frekvence“ (efektivní přenosová rychlost v Gb/s na 1 bit šířky) paměti je o tolik vyšší než u GDDR6X. Dokonce by podle Nvidie měla být lepší i energetická efektivita.


L2 cache
GPU Blackwell mají navíc také poměrně velkou L2 cache, která může hrát srovnatelnou roli jako Infinity Cache (L3 cache) v GPU od AMD – Blackwell L3 cache nemá, L2 je v hierarchii poslední stupeň před samotnou pamětí. Zdá se, že kapacity paměti L2 jsou v GPU generace Blackwell beze změny proti odpovídajícím čipům generace Ada Lovelace (RTX 4000), až na případ GB202. Toto GPU má 128 MB L2 cache proti 96 MB u předchůdce AD102.
Zdá se nicméně, že z této štědré kapacity L2 cache bude mít GeForce RTX 5090 dost velkou část vypnutou, v tomto herním modelu je z ní aktivních jen 96 MB. Plnou cache bude mít asi jen nějaká serverová nebo workstation verze grafiky s čipem GB202. Podobné to bylo i u RTX 4090.

GeForce RTX 5090 s čipem GB202
Menší GPU v řadě
Čip GB203, který bude osazen v GeForce RTX 5080 a 5070 Ti, má velikost jen 378 mm² a má obsahovat 45,6 miliardy tranzistorů. Je zajímavé, že je to o trošku méně než v čipu AD103 minulé generace (45,9 miliardy), který byl i o vlásek větší (378,6 mm²). Z tohoto se zdá, že Nvidii se podařilo při víceméně stejné výrobní technologii 4N od TSMC a stejné hustotě tranzistorů dostat v generaci Blackwell na jednotku plochy nějaké nové technologie navíc a více výkonu – pokud tedy nárůst výkonu u GeForce RTX 5080 proti RTX 4080 nebude dán jen navýšením spotřeby z 320 na 360 W (a tím frekvencí). Architektura Blackwell by ale sama o sobě měla při stejné frekvenci dávat o něco lepší výkon, takže to, že nepotřebuje o moc víc místa na čipu, je zajímavé.
Toto GPU je tvořeno 7 bloky GPC, 42 bloky TPC a 84 SM. Celkem má tedy 10 752 shaderů, 84 RT jader, 336 texturovacích jednotek a 336 tensor jader. GPU obsahuje 64 MB L2 cache, stejně jako předchozí AD103 v GeForce RTX 4080.
Z počtu 7 GPC vyplývá počet 112 jednotek ROP. Toto GPU má jen 256bitovou paměťovou sběrnici. Nvidia tedy přeskočila 384bitovou konfiguraci, u GeForce RTX 5080 bude šířka pamětí poloviční (a kapacita také) a jen trochu to bude kompenzovat vyšší frekvence, protože u tohoto modelu poběží GDDR7 na 30,0 GHz efektivně (je však pravda, že počet výpočetních jednotek je dokonce ještě méně než poloviční proti GB202, není to tedy v nerovnováze).

GeForce RTX 5070 Founders Edition
GB205 pro levnější karty
Třetím čipem v řadě je GB205, GB204 neexistuje a náhradou minulého AD104 je právě až GB205. Plocha tohoto GPU, které se dle Nvidie skládá z 31,1 miliardy tranzistorů, je 263 mm², výrazně méně než u čipu AD104 (294,5 mm² s 35,8 miliardy tranzistorů), takže Nvidia bude mít při předpokladu stejně naceněných karet RTX 5070 (které toto GPU budou používat) větší marži, nebo může grafiky prodávat za nižší ceny než RTX 4070.
V tomto případě je menší plocha čipu ale způsobená tím, že GB205 má slabší parametry. Zatímco AD104 obsahuje 60 bloků SM, čip GB205 má jen 50 SM (5 GPC, 25 TPC), což je v plné konfiguraci 6400 shaderů, 50 RT jader a 200 tensor jader – RTX 5070 ale bude mít osekanou konfiguraci s jen 6144 shadery, bude se v ní tedy dát upotřebit i čip s nějakým defektem.
Stejně jako AD104 má čip 192bitovou paměťovou sběrnici, ale už umí paměti GDDR7 stejně jako vyšší sourozenci. Kapacita L2 cache je 48 MB stejně jako u AD104 a GPU má i stejných 80 ROP.
Článek pokračuje na další straně.
Architektura Blackwell
SM a shadery
Jeden blok SM nadále obsahuje 128 „shaderů“, 512kB soubor registrů a 128kB L1 cache. Těmto shaderům či shaderovým jednotkám Nvidia nepřesně říká „CUDA jádra“, ale ve skutečnosti v GPU představuje jedno „jádro“ celý blok SM, jednotlivé shaderové jednotky jsou jen „pruhy“ SIMD jednotek tohoto jádra.
Nvidia v této nové architektuře změnila schopnosti shaderových jednotek. Dříve polovina jednotek uměla počítat běžné floating-point operace, které jsou u grafických aplikací výchozím „chlebem“ GPU, druhá polovina přidaná od generace Turing uměla počítat doplňkové celočíselné operace. Od generace Ampere byla tato druhá sada jednotek generalizována a umí jak INT, tak FP operace.
Nyní Nvidia udělala to, že stejné schopnosti dala i první polovině jednotek, takže nyní všechny shadery mohou zpracovat buď INT, nebo FP operaci (nikoliv obojí najednou). Výkon čistě v FP32 operacích se tímto nezmění. Narůst by mohl tehdy, pokud běžící kód obsahuje více než polovinu celočíselných operací, což je asi méně typické, nebo aspoň části, kde INT dominuje.
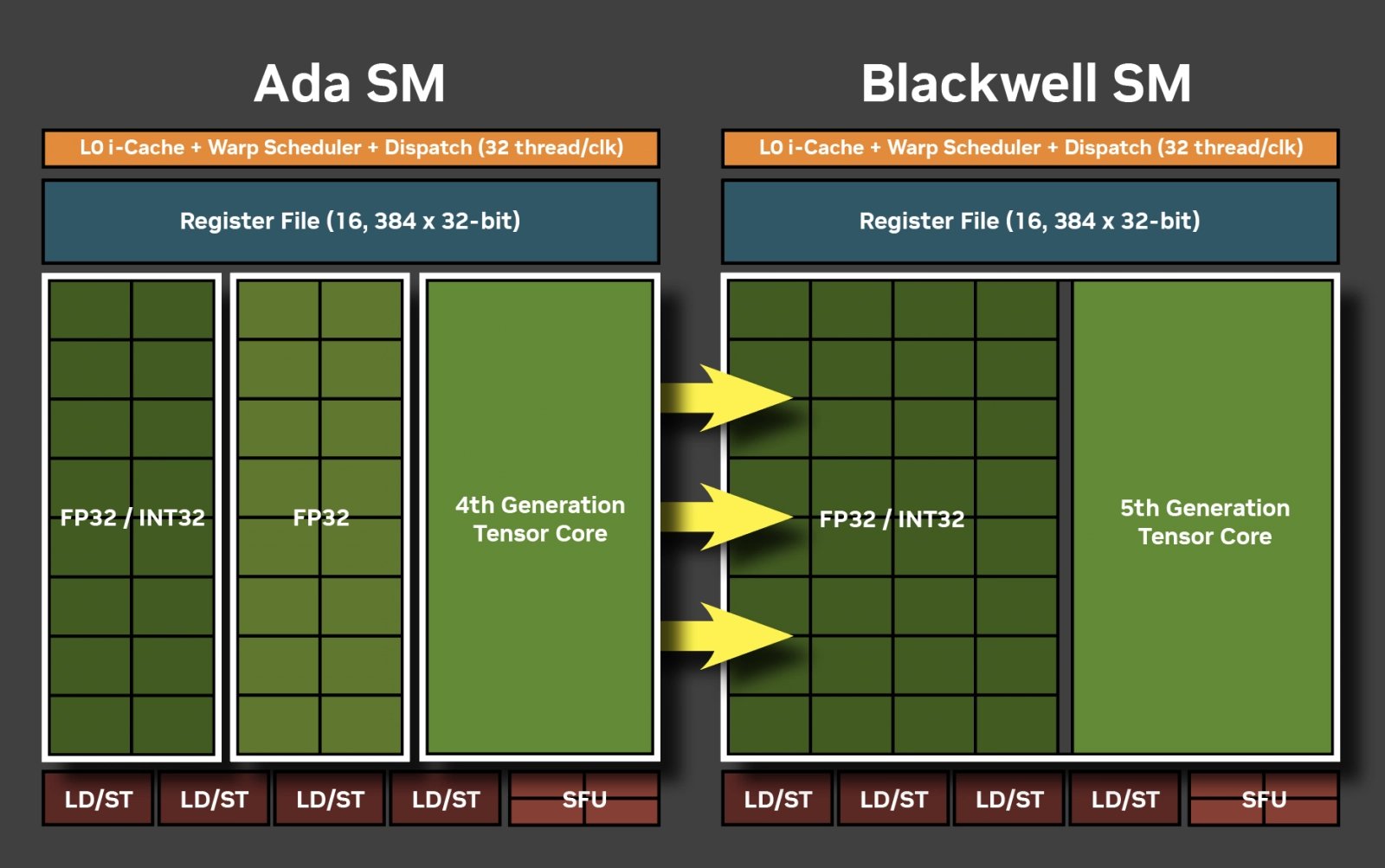
Blok SM architektury Blackwell
Těchto 128 shaderů má standardní jednotky podporující 32bitovou přesnost. Separátně jsou v každém bloku SM také jednotky pro výpočty s dvojitou přesností (FP64), ale jsou jen dvě (proti 128 jednotkám FP32/INT32). Operace FP64 tedy GPU umí zpracovávat jen s výkonem 1/64 plného výkonu v FP32 – je to víceméně jen pro kompatibilitu.
Vylepšený Shader Execution Reordering
Vedle toho shadery architektury Blackwell mají vylepšené vykonávání operací mimo pořadí (SER 2.0 neboli Shader Execution Reordering 2.0) proti architektuře Ada Lovelace. Logika provádějící dynamické řazení operací má být až 2× efektivnější (těžko ale říct, jak je to měřeno). SER 2.0 má mít menší režii a lepší schopnost najít příležitosti ke zlepšení výkonu.
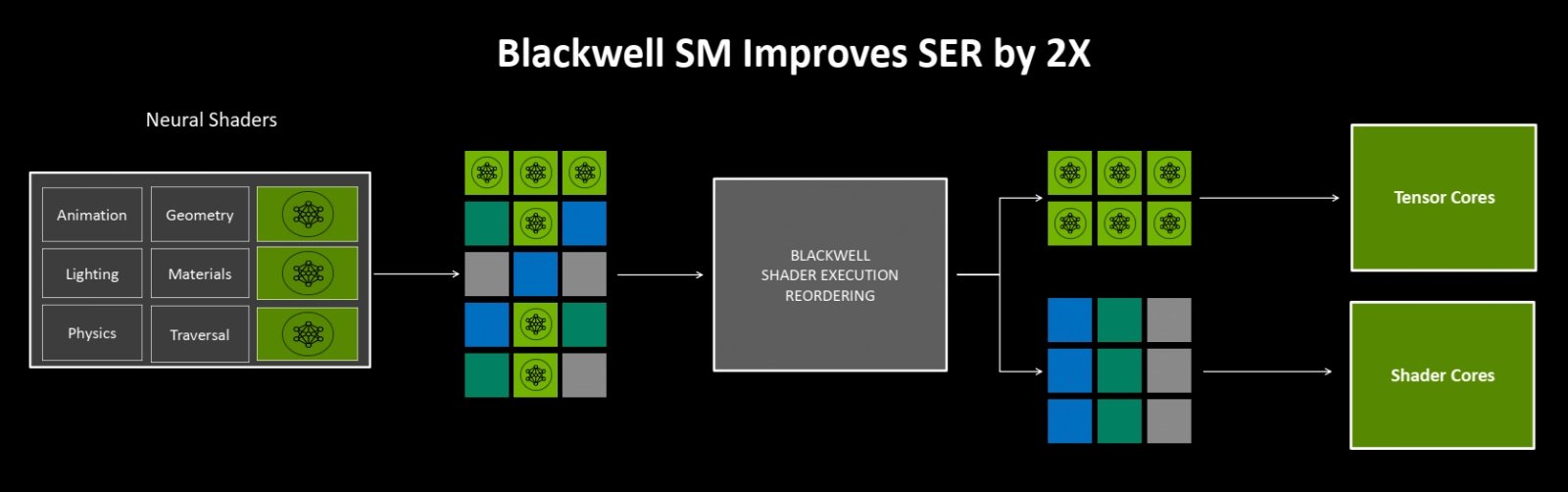
Shader Execution Reordering 2.0
Tato schopnost SER není aktivní globálně a neustále, ve výchozím stavu ji GPU nepoužívá, a není to tedy úplně ekvivalent out-of-order execution u CPU. Nvidia uvádí, že vývojáři hry mohou SER zapnout volitelně skrze API. Zřejmě nemusí mít vždy pozitivní efekt na výkon, takže využití této technologie je „opt-in“. Vývojáři ji mohou použít pro funkce, u kterých profilováním zjistí, že v nich SER zvýší výkon. Zatím asi není využití této technologie ve hrách zrovna široké (uvedena byla už v GeForce RTX 4000), Nvidia uvádí, že už ji používá „několik her s ray tracingem“.
Neural shadery
Nová u shaderů architektury Blackwell je kompatibilita s tzv. Neural Shadery. Tou jsou operace využívající tensor jádra, ale ne jako samostatnou jednotku, ale přímo ze shaderových programů běžících na shaderech v SM. Funguje to tak, že v takovém shaderovém programu je vlastně volána nějaká předtrénovaná neuronová síť s nějakým poměrně malým modelem.
Toto dříve nebylo možné, protože tensor jádra nebyla s shaderovými jednotkami úzce propojená. Jde to právě až v GPU architektury Blackwell (poznámka: toto je něco, co architektury AMD možná nemusí řešit, protože u nich je alespoň nyní jejich forma akcelerace AI integrovaná do klasických výpočetních jednotek s použitím stejných pracovních registrů a použití klasických shaderových instrukcí a instrukcí WMMA akcelerujících AI v jednom shaderovém programu je nejspíš možné automaticky – nevíme ovšem, zda se tento přístup nezmění u budoucí architektury UDNA).
Stochastic Texture Filtering
Nvidia pro Blackwell navrhuje techniku Stochastic Texture Filtering, která se používá jako určitá náhrada za složitější (trilineární, anizotropické) filtrování a využívá principu, že je výsledek částečně randomizován. Přidání šumu může předcházet artefaktům, jako je moiré. Blackwell má pro potřeby této techniky v texturovacích jednotkách 2× vylepšený výkon nefiltrovaného (nearest-neighbor) interpolování. V tomto kontextu je zajímavé, že i architektura AMD RDNA 3.5 (a možná tedy i RDNA 4) přidává podporu pro akceleraci nefiltrované interpolace při texturování, možná také pro toto stochastické filtrování.
Nová tensor jádra: Podpora FP6 a FP4
Tensor jádra jsou už v páté generaci a jejich nová architektura přináší podporu pro operace s přesností FP4. Toto umožňuje provést dvojnásobek operací proti výpočtům s 8bitovou přesností INT8 či FP8. Současně uložení dat modelu o určitém počtu parametrů potřebuje jenom polovinu kapacity paměti proti modelu s 8bitovou přesností.
Ale nevýhodou je extrémně nízká přesnost těchto hodnot, respektive je otázka, zda se o přesnosti ještě dá mluvit. FP4 by mělo dávat jen dva bity (čili jen čtyři možné hodnoty) pro exponent a jeden bit čili dvě hodnoty pro mantisu, čtvrtý bit je znaménko. Zdá se ale, že pro AI využití je navrhován i formát s 3bitovým exponentem a žádnou mantisou. Báze by měla být stále dva, jde stále o binární floating-point čísla. Takovéto datové typy lze možná chápat spíš jako cosi na pomezí expresivnějšího upgradu logické hodnoty true/false (což je jednobitová hodnota) a klasické proměnné ukládající čísla.
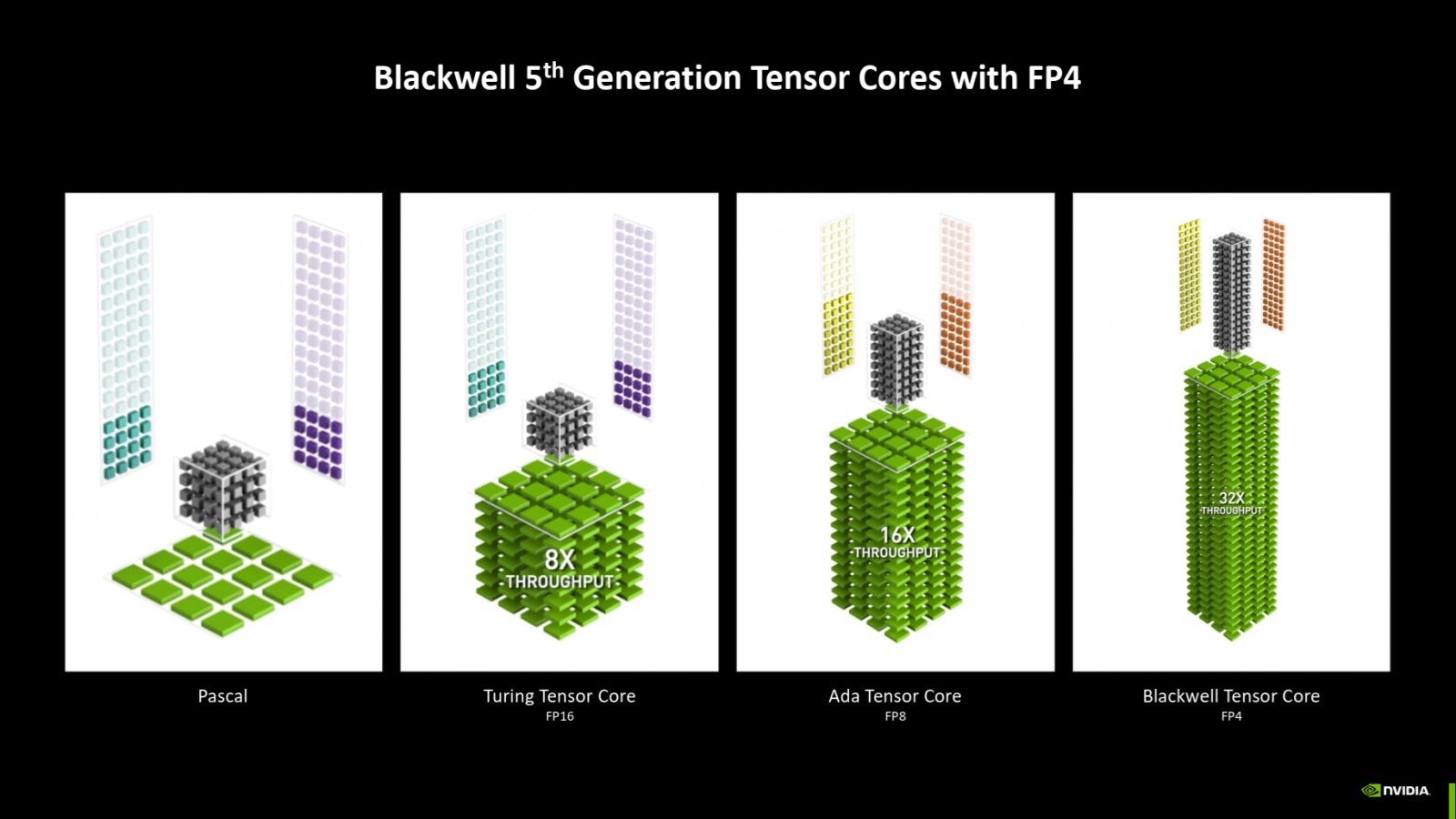
Tensor jádra 5. generace podporují datový typ FP4
Neuronové sítě (AI modely) jsou obecně překvapivě kompatibilní s nízkou přesností dat – alespoň při inferenci – proti tomu, jakou přesnost byste potřebovali pro obvyklé numerické výpočty. U INT8/FP8 už ale bývá pozorována zhoršená kvalita výsledků, což se u INT4 nebo FP4 musí projevit o to víc. FP4 model se stejným počtem parametrů jako FP8 by asi měl mít horší výsledky. Je proto možné, že použití těchto hodnot bude omezené jen na některé aplikace, nebo se bude muset různě kompenzovat (třeba tím, že ve 4bitové přesnosti bude jen část výpočtů, nebo že bude model mít více parametrů). Ono dvojnásobné škálování výkonu tedy asi nemusí být něco automatického.
Jak bylo zmíněno, důležitá může být schopnost se 4bitovými hodnotami vměstnat model o určitém počtu parametrů na GPU s malou pamětí (třeba 32 GB místo 64 GB), ale vždy u toho bude ona nevýhoda horší kvality, takže je otázka, jak kompromisní toto v praxi bude. Alternativou k FP4 ještě může být datový typ FP6, který Blackwell také nově podporuje. U toho už asi nebude dvojnásobný výkon a jeho smyslem je patrně úspora paměti.
Tensor jádra v herních čipech Blackwell mají po softwarové stránce umět stejný typ neuronových sítí (kterému Nvidia říká transformer engine 2. generace) jako serverová verze Blackwellu GB200.
RT jádra s 2× výpočetním potenciálem
Akcelerátory RT core (jeden v každém bloku SM) jsou u GPU Blackwell ve čtvrté generaci. Jejich hlavní novinkou je dvojnásobná kapacita pro zpracování průsečíků paprsků s trojúhelníky objektů ve scéně za jeden cyklus frekvence. U Ada Lovelace by RT jádro mělo zvládat 4 průsečíky za cyklus, pokud máme správné informace, takže u Blackwellu by to snad mohlo být 8 za cyklus.
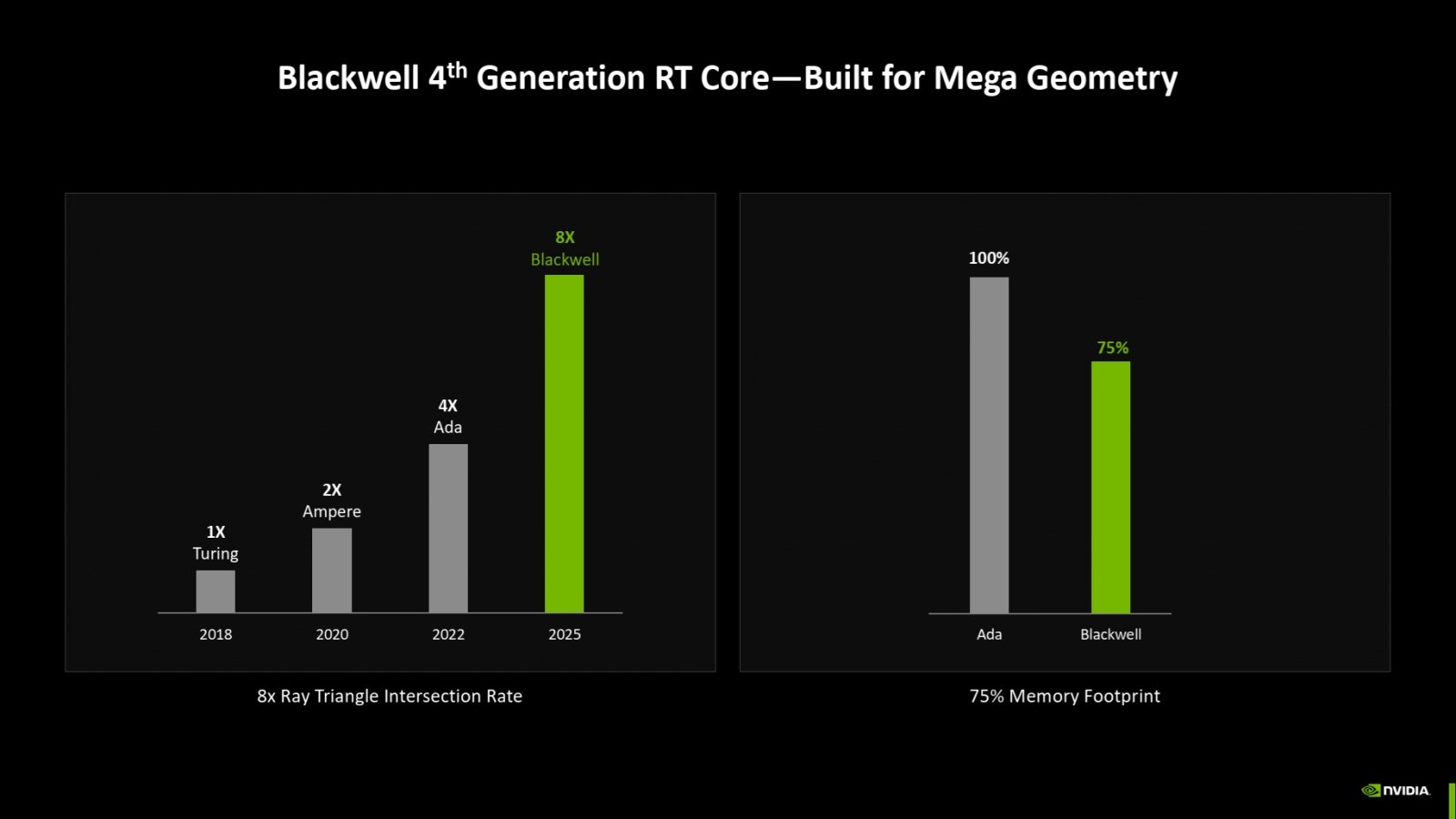
RT jádro generace Blackwell má 2× vyšší výkon dostupný pro analýzu průsečíků paprsků světla a trojúhelníků 3D modelu
Počet zpracovatelných průsečíků paprsků a boxů BVH není uveden ani není zmíněno jeho zlepšení. To by ale snad nastat mohlo, protože u Ada Lovelace snad také byly podporovány čtyři za cyklus a je divné, že by bylo podporováno méně operací na úrovni pomocných boxů BVH než se samotnými trojúhelníky.
Článek pokračuje na další straně.
Nové technologie čipů Blackwell
PCI Express 5.0
Blackwell přináší podporu nové generace PCI Expressu – respektive, novější. PCIe 5.0 byl očekáván už od minulé generace Ada Lovelace v roce 2022, toto rozhraní totiž již poskytují desky platformy LGA 1700 (o nové LGA 1851 nemluvě) a procesory Intel Alder Lake od roku 2021. U AMD pak rozhraní umí Ryzeny 7000 (a 9000) na platformě AM5 od roku 2022. Specifikace byla hotová v roce 2019 a od roku 2021 už je venku specifikace následujícího PCI Expressu 6.0 s dvojnásobnou rychlostí, letos má být dokonce hotová technologie PCIe 7.0. Lze tedy říci, že herní GPU (všech značek, nejen Nvidia) mají v tomto případě velké zpoždění. Jak GB203, tak i toto GB205 podporují PCI Express 5.0 stejně jako highendové GB202.
PCI Express 5.0 každopádně přináší dvojnásobnou propustnost rozhraní mezi procesorem a systémem počítače a grafickou kartou. S PCIe 5.0 ×16 je to až 64 GB/s (v obou směrech, PCIe je duplexní). Alternativně to lze využít tím, že když GPU dostane jen osm linek (×8) třeba u desek, které část linek ze slotu pro grafiku odklánějí do slotů M.2 pro SSD, pořád bude mít stejnou propustnost, jakou dávalo plnotučné rozhraní PCIe 4.0 ×16. Efekt propustnosti mezi GPU a zbytkem CPU může být o něco vyšší u výpočetních aplikací, každopádně ale rychlejší PCI Express zvedá strop jednoho z potenciálních „úzkých hrdel“ výkonu, byť se na něj nemusí narážet moc často.
Web TechPowerUp otestoval škálování výkonu s různými generacemi PCI Expressu na GeForce RTX 5090 a vyšlo mu, že tato grafika z PCIe 5.0 ×16 již trošku profituje, jinými slovy při použití jen PCIe 4.0 ×16 (nebo PCIe 5.0 ×8) je o něco nižší výkon – byť ne nijak významně. Rozdíl je v průměru jen asi 1 %, ale u některých her jsou vidět výjimky (větší propady například ve hře No Rest For The Wicked). Až starší PCI Express 3.0 ×16 (nebo ekvivalentní PCIe 4.0 ×8) má větší postih s asi 4% průměrnou ztrátou výkonu. Poklesy jsou obvykle drsnější v rozlišeních 2560 × 1440 a 3840 × 2160 a nižší v 1920 × 1080. Ale mezi testovanými hrami některé fungovaly i obráceně s drsnějšími propady při hraní na 1920 × 1080. Je ale možné, že tato nekonzistence byla někde způsobená problémy či chybami ovladačů.
DisplayPort 2.1b
Blackwell také splácí další dluh, respektive přináší věc, která se čekala už od předchozí generace, ale podporována nebyla, a sice konečně podporu DisplayPortu 2.0/2.1 pro připojení monitorů s vyšším rozlišením a obnovovací frekvencí. Či alternativně s nižší úrovní ztrátové komprese, která je dnes u monitorů používána. V tomto případě šlo na rozdíl od PCIe 5.0 o větší dluh, protože DisplayPort 2.1 už byl podporován některými grafikami předchozí generace – Radeony RX 7000 a kartami Intel Arc generace Alchemist (novější generací Battlemage také).
Grafiky GeForce RTX 5000 už umí DisplayPort 2.1b s podporou delších aktivních kabelů. Výstup je podporován i v nejrychlejším (co do přenosové kapacity) režimu UHBR20 s propustností 77,37 Gb/s (prakticky trojnásobnou proti datové propustnosti rozhraní DisplayPort 1.4a, které bylo maximem u GPU generace Ada Lovelace/RTX 4000).
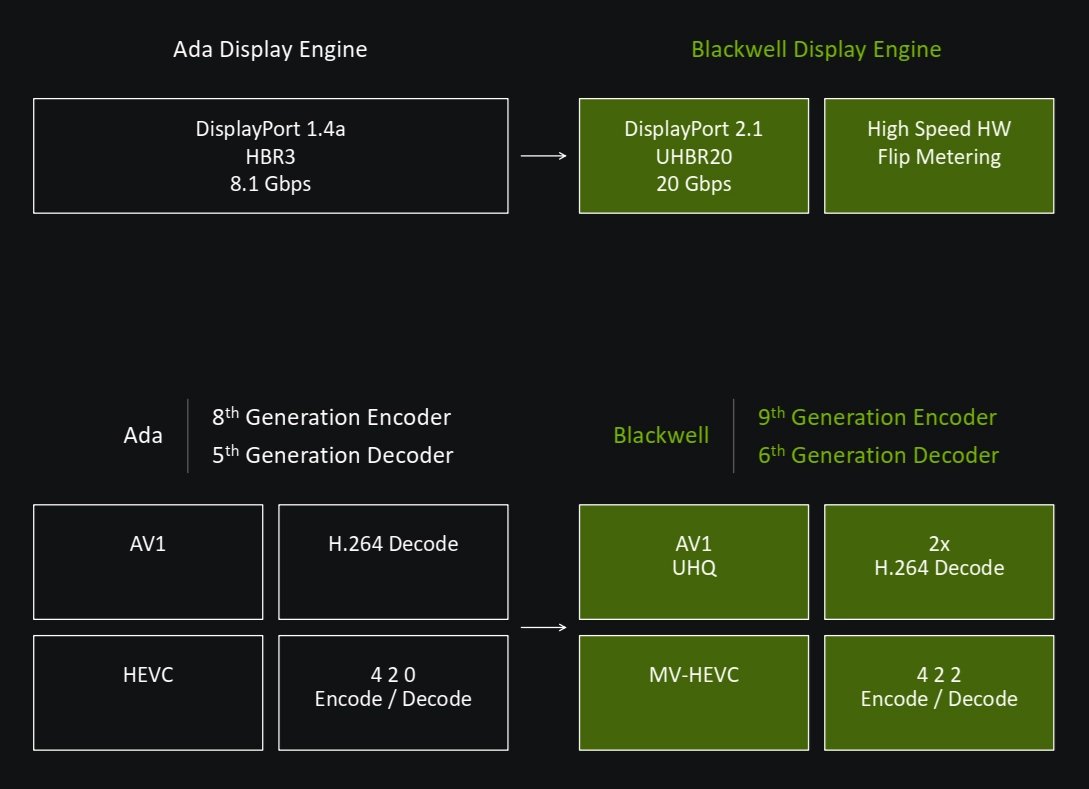
Nvidia Blackwell – obrazový výstup a video
GPU Blackwell díky DP 2.1 už – jako Radeony RX 7000 – podporují rozlišení 8K až při 165 Hz (doteď bylo maximum karet GeForce 60 Hz) nebo 4K při až 480 Hz. Dokumenty Nvidie zmiňují, že UHBR20 bude vyžadovat aktivní kabely (DP80LL zavedené v DP 2.1b), zatímco konkurenční karty by měly UHBR20 umět i na pasivních kabelech do délky 1–1,2 metru (UHBR20 umí Radeony Pro s architekturou RDNA 3, ne však herní karty, které podporují UHBR13.5). Zda GeForce RTX 5000 toto nezvládají, je něco, co bude ještě třeba vyjasnit. Alespoň UHBR13.5 by ale mělo fungovat i s běžným levným kabelem.
Nadcházející HDMI 2.2 architektura Blackwell nepřináší, ale to se ani čekat nedalo, specifikace ještě ani není hotová.
Multimediální akcelerace: Inkrementální zlepšení
GPU by na druhou stranu měla mít o generaci novější multimediální enginy (9. generace NVEnc, 6. generace NVDec). Dekodéry jsou v počtu jednoho (RTX 5070 Ti, RTX 5070) nebo dvou, enkodérů je na čipu až trojice (u RTX 5090), ale méně u nižších modelů (RTX 5070 má jen jeden). Nevíme ale, zda jsou toto skutečné maximální parametry čipů. U herních karet mohou některé jednotky být uměle vypnuté, bylo to tak i v předchozí generaci.
Ty multimediální enginy jsou také nové generace, ale vypadá to, že neumí nové formáty (chybí akcelerace formátu VVC, kterou má zatím jen procesor Intel Lunar Lake / Core 200V). Má však být vylepšená kvalita komprese do AV1 a přibylo další kvalitnější nastavení komprese „Ultra Quality“. Nvidia uvádí zlepšení komprese (respektive metriky BD-Rate PSNR a BD.BR VMAF) o 4–18 %.
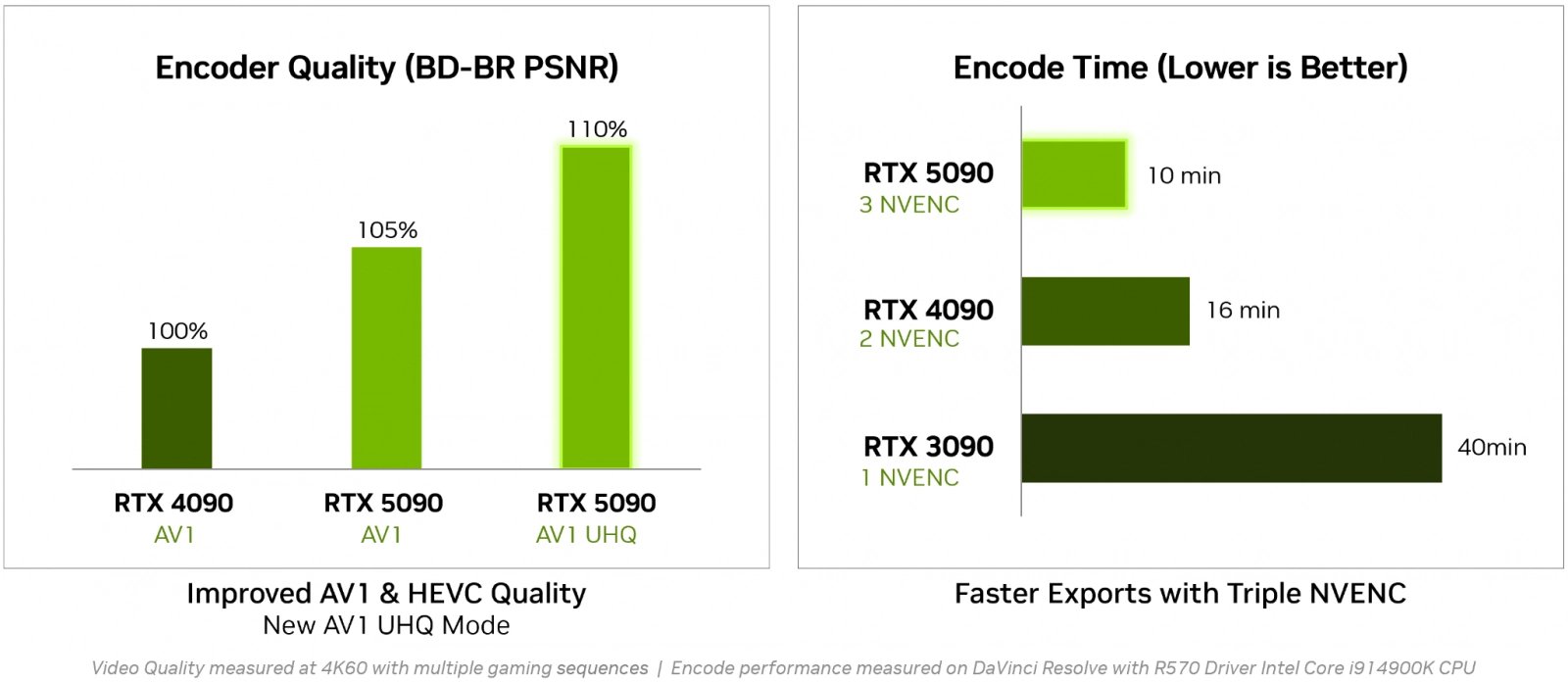
Enkódování AV1 na GPU Blackwell
Nvidia také přidala podporu 4:2:2 subsamplingu chrominance v YUV barvách pro některé formáty (HEVC a H.264). Toto kódování používají některé profesionální výstupy z kamer.
Data o teplotě hotspotů nebudou přístupná
Věc, která možná bude trápit overclockery, je odstranění informace o teplotě tzv. hot spotu (takže ji neuvidíte třeba v programu HWiNFO). To nebyl nějaký konkrétní senzor, ale informace o tom, jaké nejvyšší teploty je na GPU v kterémkoli ze senzorů dosaženo. V čipu by mělo být senzorů teploty větší množství, takže tento údaj dává lepší informaci navíc k průměrné teplotě, identifikující potenciální lokální přehřívání čipu.
Potenciální využití této informace by mohlo být, například když je špatně nasazený chladič nebo nanesená pasta – velká diskrepance mezi průměrnou teplotou (která může pořád vypadat nevinně) a teplotou hotspotu doteď mohla být použitá jako určité varovné znamení. Není známo, z jakého přesně důvodu není u GPU Blackwell informace o hotspotové teplotě zpřístupněna uživateli. Podle Nvidie tato čísla nikdy nebyla příliš užitečná, ale asi to bude budit podezření, že údaj mohl působit nelichotivě – zejména třeba u nejvyššího modelu RTX 5090 s jeho 575W TDP.
Článek pokračuje na další straně.
Software a novinky ve výbavě
Mega Geometry
Vedle toho má být fungování RT jader v generaci Blackwell posíleno i o nějaké nové schopnosti hardwarově-softwarového rázu, které zřejmě budou využitelné až při jejich zakomponování do nových her. Nová je například podpora objektů typu Subdivision Surface a Linear Swept Spheres.
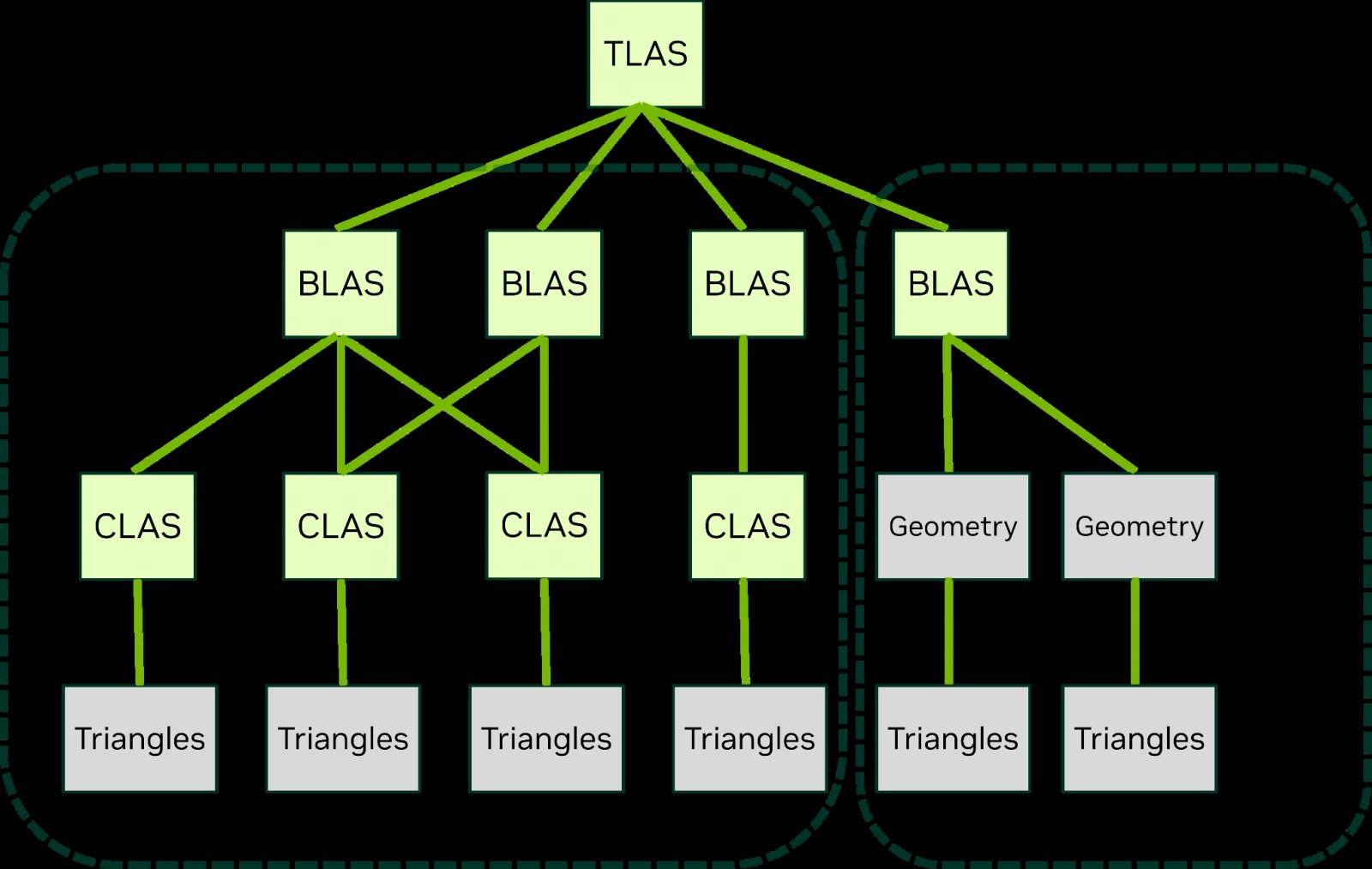
Softwarového rázu by měla být funkce Mega Geometry, která má vylepšovat výkon při práci s mnoha objekty ve scéně, pro něž je třeba počítat ray tracing. Umožňuje sdružit trojúhelníky do větších struktur (clusterů CLAS). Jedna z užitečných aplikací by měla být, že tyto clustery se budou snáze nahrazovat za jiné, což je něco, co probíhá například při vzdalování objektu, kdy ho engine hry nahradí modelem s menším počtem trojúhelníků (nižší úrovní detailů). Nahrazení modelů ale při raytracingových efektech vyžaduje sestavení nové hierarchie pomocných boxů (BVH) pro analýzu těchto nových modelů, což stojí dost výkonu, a změna úrovně detailů u mnoha objektů tak může být příčinou velkých propadů FPS.
Mega Geometry
Mega Geometry a zpracování objektů po clustrech má tento proces usnadnit a zjednodušit, takže takové operace ve hrách budou potřebovat méně výkonu. Současně by práce v tomto režimu měla dělat více operací plně v rámci GPU bez toho, aby se muselo zapojit CPU systému, takže použití těchto technik zmenší režii hry v ovladačích a může zmírnit limitaci výkonem CPU. Nvidia píše, že by mělo jít o technologii užitečnou například pro Unreal Engine 5 s jeho technologií geometrie Nanite.
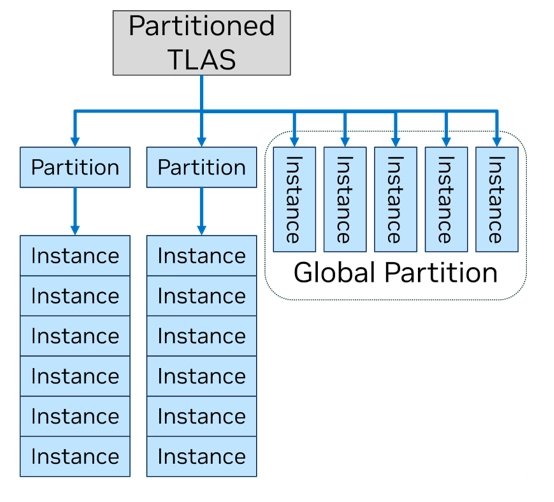
Vedle těchto clusterů také technologie Mega Geometry přináší organizaci geometrie a objektů do oddílů neboli partitions (PTLAS). Ta se dá použít k tomu, že se objekty, které jsou ve scéně statické, vydělí do separátních oddílů. Aktualizace geometrie v každém snímku se pak dá udělat tak, že se oddíly (PTLAS) se statickými objekty pro daný snímek přeskočí ve zpracovávání, a nejsou tedy počítány pro každý snímek jako ty objekty, které se pohybují.
Mega Geometry
Podpora i ve starších GPU
Mega Geometry by měla být podporovaná v DirectX 12 přes NVAPI, ve Vulkanu pomocí rozšíření (vendor extension) a také v API OptiX 9.0 pro renderovací softwary. Podpora by měla být i na starších grafikách od RTX 2000 výše, takže zřejmě není přímo závislá na nějakých architektonických rysech GPU Blackwell (nejde patrně o něco integrovaného přímo v hardwaru).
Komprese dat BVH struktur
GPU Blackwell by ale podle Nvidie měla mít vylepšenou kompresi pro BVH struktury, které pak u těchto GPU budou v paměti zabírat méně místa – údajně to může dělat až pár stovky megabajtů (200 až 300 MB?) rozdílu proti předchozím GeForce ve hrách s náročnou geometrií a ray tracingem jako tituly používající UE5 a Nanite. Ovšem jde jenom o kompresi dat používaných při ray tracingu, neprojeví se to tedy při hraní bez něj.
DLSS 4: Nová neuronová síť a víc umělých snímků
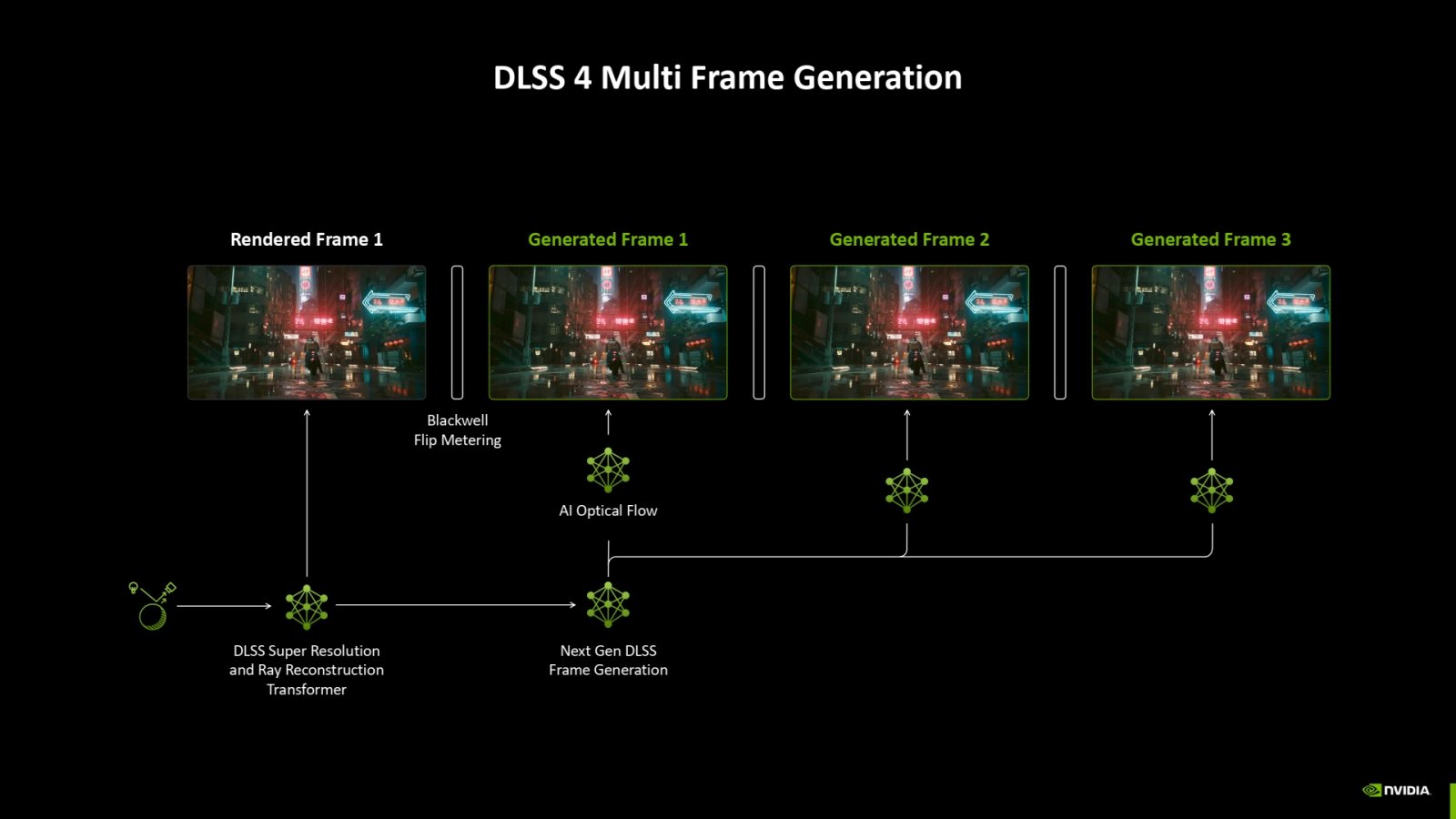
Jednou z ústředních „technologií“ u GeForce RTX 5000 je DLSS 4. Jejím jádrem je rozšíření techniky generování snímků z DLSS 3. Ta doteď přidávala jeden interpolovaný (umělý, nepravý) mezisnímek mezi každé dva reálně vykreslené snímky hry, tedy jinými sloty 50 % snímků bylo reálných, 50 % uměle dointerpolovaných. O tom, jak generování snímků probíhá a jaké to má výhody či nevýhody, jsme psali zde:

Novinka v DLSS 4 je tzv. „Multi Frame Generation“, což není nic jiného, než že se nyní mezi reálné snímky vkládá více umělých dointerpolovaných. Mohou to být dva snímky (66 % „umělých snímků ve výsledném výstupu“, teoreticky 3× FPS proti reálné frekvenci hry), nebo tři snímky, což znamená, že 75 % snímků, které uvidíte, je uměle dointerpolovaných (což znamená potenciálně horší kvalitu) a jen 25 % reálných. Můžete ale teoreticky mít 4× vyšší koncové FPS, než hra a GPU reálně vykreslují.
Nevýhoda je, že zatímco při zobrazení 50 : 50 se asi celkem dobře rozplynou případné chyby v interpolovaných snímcích, nyní většinu času vidíte umělé snímky, takže už to může fungovat spíš obráceně a ve vjemu může dominovat „interpolovaná kvalita“.
DLSS 4 Multi Frame Generation
Pro připomenutí: vkládání generovaných snímků o něco zvyšuje latenci hry, protože nejprve musíte mít hotové oba krajní snímky sekvence, mezi nimiž se interpoluje, a až poté můžete začít generovat. To znamená, že zobrazení musí být vždy o kousek pozadu za hrou. Jen bez použití generovaných snímků lze nově vypočítaný snímek okamžitě zobrazit na monitoru.
Nvidia toto kompenzuje technologií Reflex, která se ale dá zapnout i bez DLSS 3 / DLSS 4 a poskytuje zkrácení latence sama o sobě (vliv Reflexu není v žádném případě přínosem funkce generování snímků, i když se to marketing často snažil míchat).
Generované snímky také nejsou plnohodnotné v tom smyslu, že nejsou výsledkem enginu hry, ten v nich tedy neaktualizuje AI protivníků, polohu objektů, projektilů a tak podobně. Generování snímků všechny pohyby a změny pouze aproximuje podle toho, jaké pozice objektů vidí na oněch dvou snímcích, mezi které „domýšlí“ ty další generované snímky.

Podpora DLSS 4 ve hrách
Vylepšený AI model
Vedle více interpolovaných snímků má DLSS 4 ještě druhou složku – přináší novější vylepšený model. Jde o neuronovou síť typu Transformer, zatímco předchozí DLSS měly konvoluční neuronovou síť. Nový model by měl o něco zlepšit kvalitu upscalingového komponentu DLSS, funkce Ray Reconstruction (novinka v DLSS 3.5) a patrně i temporální rekonstrukce, jelikož Nvidia zmiňuje lepší stabilitu obrazu mezi snímky (méně shimmeringu, ghostingu, rozmazání pohybu, blikání…). Tato část DLSS 4 bude fungovat i na starších grafikách – od GeForce RTX 2000.

Ukázka přínosů nové neuronové sítě typu Transformer v DLSS 4, snímek Nvidie
Nicméně mnohosnímkové interpolování je omezeno jen na nové karty RTX 5000. A to paradoxně přesto, že nepoužívá nějaké speciální hardwarové jednotky. Toto je překvapení, protože interpolace snímků v předchozím DLSS 3 je naopak závislá na hardwarových jednotkách v čipech Ada Lovelace. DLSS 4 od nich ale upustilo a používá jen tensor jádra, je tedy v určitém smyslu softwarové (v rámci toho, že jde stále o neuronovou síť běžící na hardwarových akcelerátorech). Jejich výkon je v nové generaci vyšší, ale i tak – když už má multisnímkové generování fungovat třeba na RTX 5070 nebo budoucích RTX 5060, pak by minimálně ve vyšších modelech předchozích generací snad mělo být výkonu tensor jader také dost. Nvidia už připustila, že by teoreticky ještě podpora starším grafikám mohla být přidána, ale zatím není nic přislíbeno.
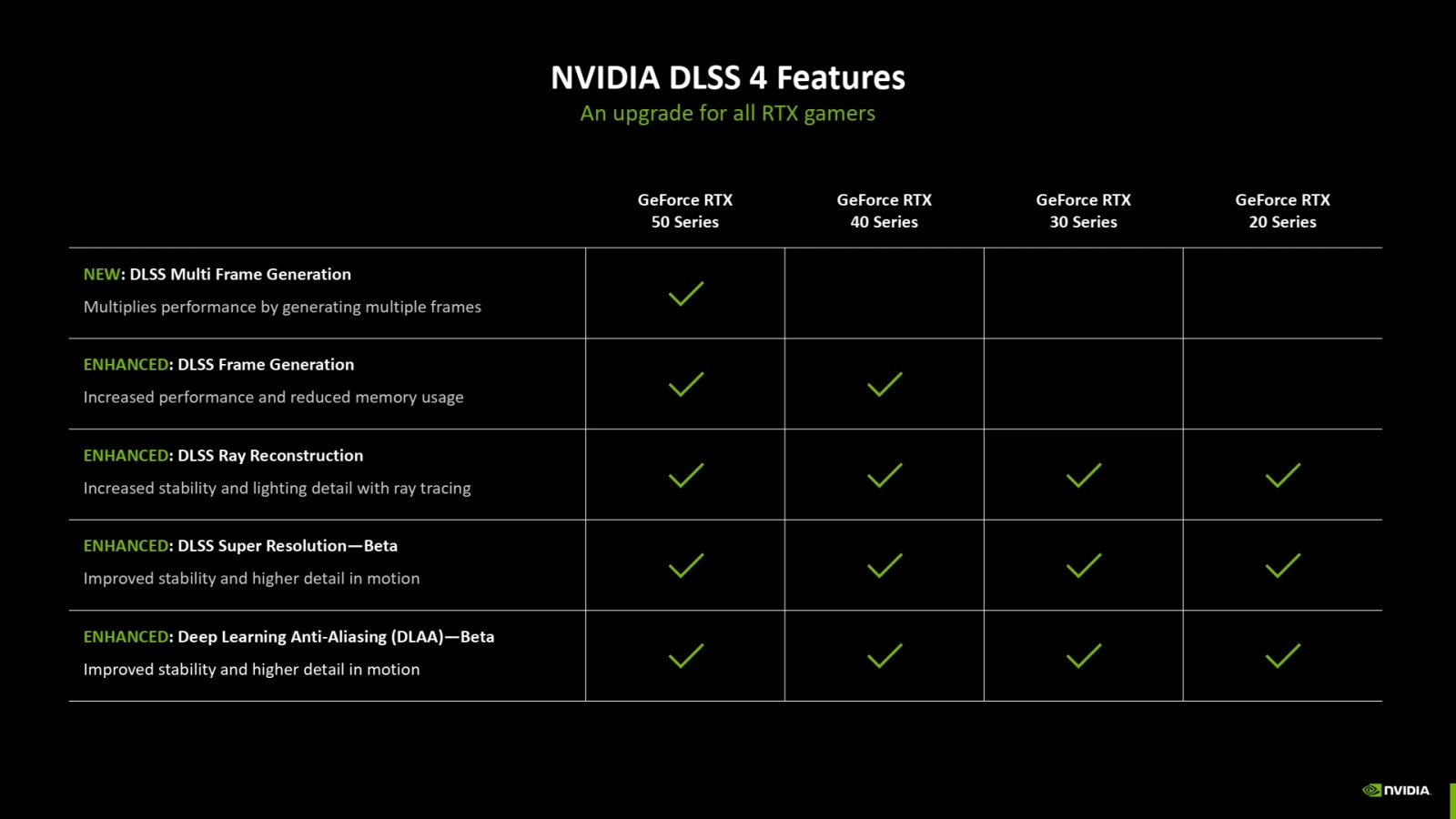
Podpora funkcí DLSS 4 na různých GPU
Momentálně by tedy měla být situace taková, že nové multiinterpolování FPS bude jen pro karty RTX 5000, GeForce RTX 4000 budou dál používat jednoduché generování snímků v režimu DLSS 3.x, zatímco GeForce RTX 3000 a 2000 generování snímků mít zpřístupněno nebudou.
Reflex 2 pro lepší latenci
A když už jsme u Reflexu, s GeForce RTX 5000 vydává Nvidia druhou generaci této technologie označenou Reflex 2, ve které je integrovaná technika Frame Warp. Jde o metodu, jak částečně zlepšit responzivnost hry při použití multiframe generování.
Reflex 2 dělá to, že přidává do snímku úpravy podle reálného pohybu kurzoru myši. Ten lze získat nezávisle na enginu hry, takže ovladač GPU můžu po dokončení vykreslování snímku mít o něco novější údaje o vstupech z klávesnice a myši, než s jakými byl snímek počítán.
Při použití Reflexu 2 je snímek upraven před jeho odesláním do monitoru – může například být globálně posunutý včetně korekce perspektivy/hloubky podle toho, jak jste pohnuli myší ovládající výhled. V takto posunutém snímku pak ovladač ještě překreslí kurzor či zaměřovač do správné pozice. Chybějící data na okraji dogenerovává interpolací, což může způsobovat artefakty či chyby (obecně takovéto zasahování do snímků podobně jako generování snímků vede k možným chybám či nepřesnostem v obrazu proti snímku, který by vykreslila přímo hra).
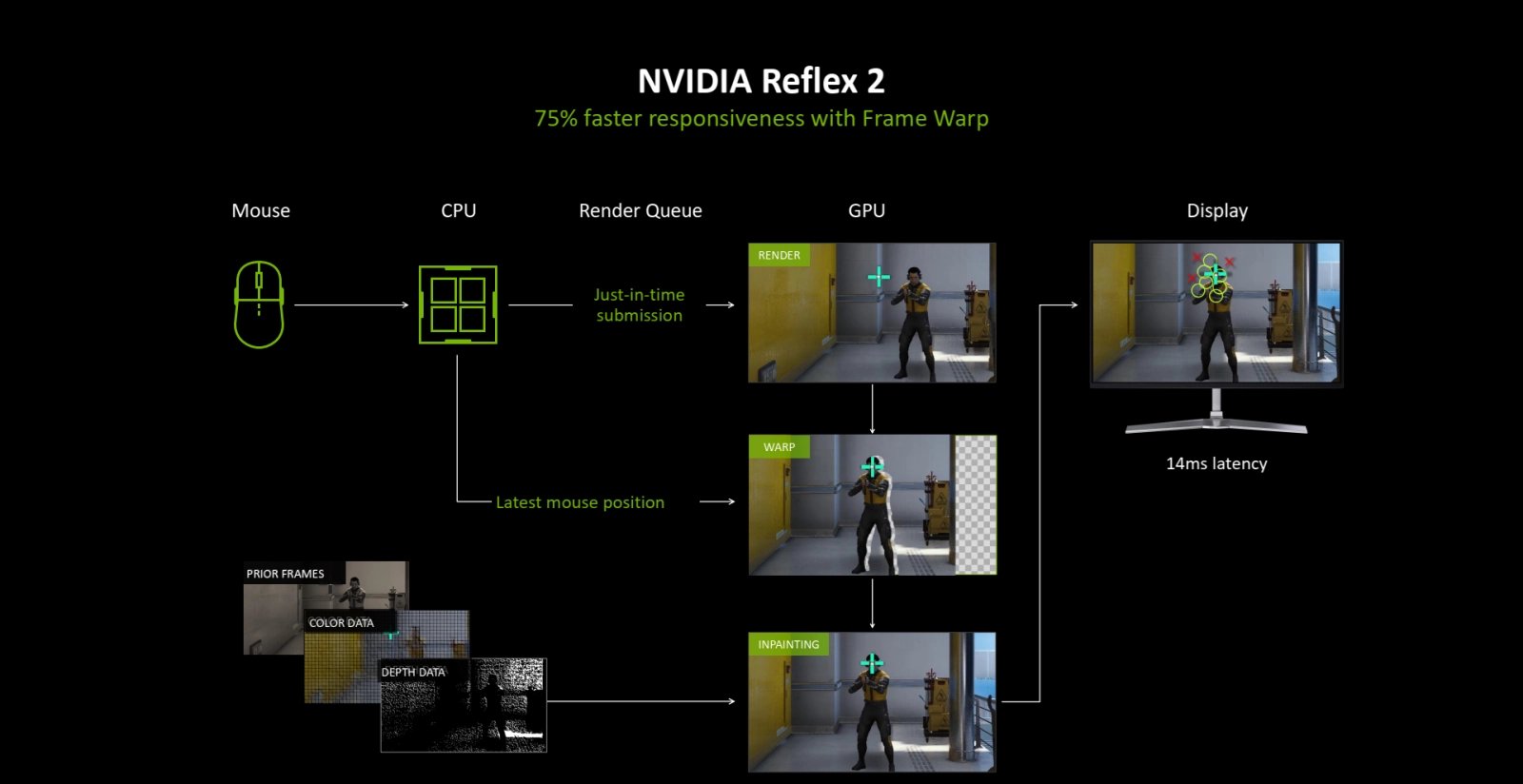
Nvidia Reflex 2 – Frame Warp
Je asi jasné, že v takto upraveném snímku lze zohlednit jen některé změny, ne cokoliv. Jako při generování snímků nemůže Reflex 2 vědět o věcech, které se podle hry mají v daném momentu stát, ale ještě nebyly vidět na snímku, který je k dispozici (zde je to omezení ale silnější, protože Reflex 2 se nemůže podívat na budoucí snímek). Redukce latence získaná pomocí Frame Warp je tak částečná, netýká se nutně všeho, co je na obrazovce zobrazováno.
Reflex 2 s touto funkcí Frame Warp by nyní zřejmě měl fungovat jen bez generování snímků. Určení této funkce je pro soutěžní hraní, mimo eSports má asi omezenou užitečnost (pokud hrajete single-player, nejsou extrémně stlačené latence asi moc důležitá věc).
„AI“ textury, materiály a osvětlení
Zmíněné Neural Shaders chce Nvidia využít pro různé softwarové technologie pro hry. Mezi nimi je technika Neural Texture Compression – aplikace neuronové sítě do komprese a zřejmě také procesu dekomprese textur, která má přinést o něco lepší kompresní poměr proti běžně používaným formátům, které se pro kompresi textur ve hrách používají nyní. Experimenty s takovými formáty byly už publikovány (nejen Nvidií), může ale trvat nějakou dobu, než se tyto techniky dostanou do nějakých her.
Dále Nvidia zmiňuje techniku Neural Radiance Cache, kde je inference přes neuronovou síť použitá ke zrychlení výpočtů osvětlení (patrně jeho aproximací a cachováním, která bude i přes použití neuronové sítě rychlejší než plný výpočet). Vykreslování pomocí Neural Radiance Cache má přeskakovat analýzu značné části paprsků světla, otázka je samozřejmě, jak poznatelný efekt to bude mít na kvalitu.
Podobného rázu mají být i techniky RTX Skin a Neural Materials. I u nich má být neuronová síť použitá k aproximování určitých kvalit a charakteristik materiálů. Jednoduchá neuronová síť má v této roli nahradit komplexnější simulace takových materiálů, jako třeba pronikání světla pod povrch u kůže.

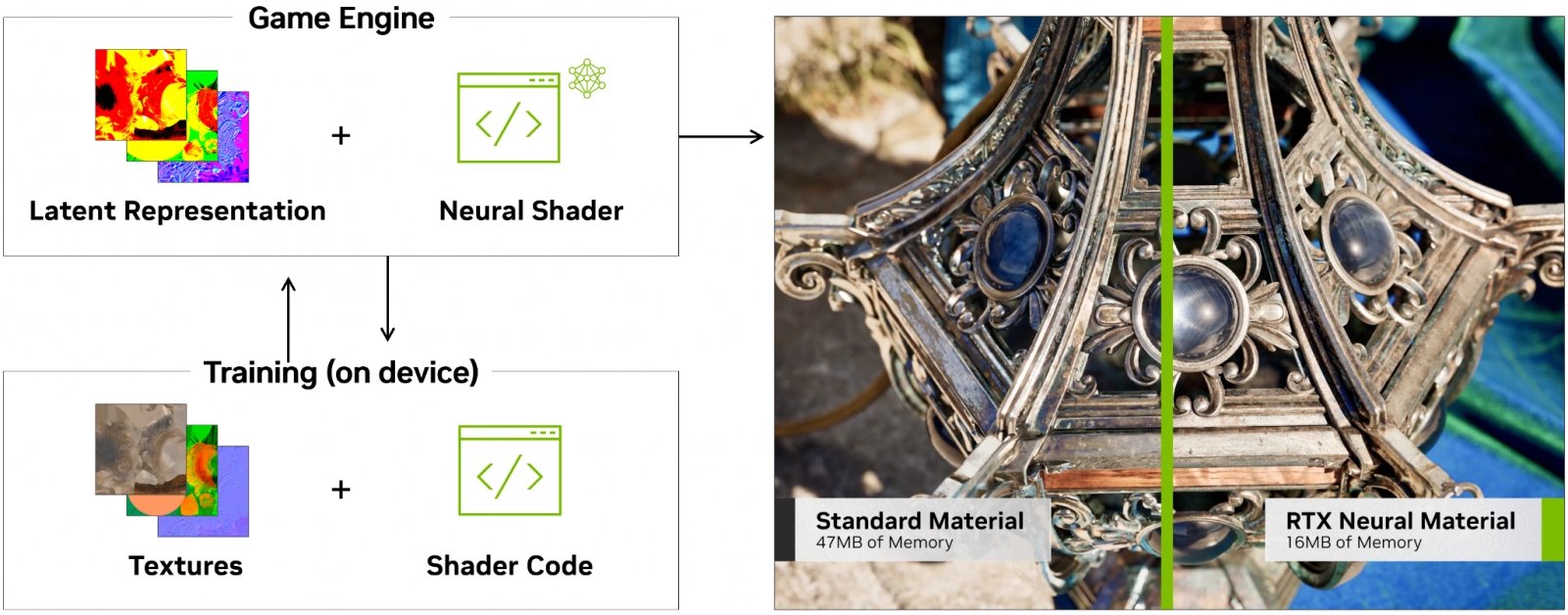
RTX Neural Materials
RTX 5000 přichází na trh tento týden
Jak to celé funguje v praxi, už částečně máte možnost vidět v recenzích. Na HWCoolingu jsme testovali GeForce RTX 5090 v provedení Founders Edition přímo od Nvidie. Tato karta bude v prodeji od 30. ledna, což by mělo současně být i datum, kdy se začne prodávat o poznání levnější model GeForce RTX 5080. Parametry všech karet jsme probírali zde:


Zdroj: Nvidia































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU