
Intel na Computexu 2024 odhalil svůj next-gen mobilní procesor Lunar Lake, který vyjde letos v létě. Ten bude svou silnou NPU pohánět Copilot+ PC a má být velmi energeticky efektivní, ale extrémně zajímavý je hlavně úplně novými architekturami CPU, které nás čekají i v budoucích procesorech Arrow Lake pro desktop. Jako na první se podíváme na architekturu velkého jádra P-Core, která přináší největší změny minimálně od Sandy Bridge.
Nové velké jádro Lion Cove
Pro hráče, i pokud se nezajímají o mobilní zařízení (přičemž tyto čipy by mohly dobře najít uplatnění v herních handheldech, jako je Steam Deck), jsou aktuální informace o Lunar Lake důležité. Procesory totiž mají stejnou architekturu jader CPU, jako nasadí i nastávající výkonnější procesory Arrow Lake, které už budou i v desktopu na nové platformě LGA 1851.
Architektura velkých jader (alias P-Core) má označení Lion Cove a je patrně úplně nová, nebo výrazně přepracovaná proti předchozím jádrům Golden Cove, Raptor Cove a Redwood Cove obsaženým v procesorech Alder Lake, Raptor Lake a Meteor Lake. Rozsah změn si nezadá se Zenem 5 od AMD, u kterého zatím všechny detaily neznáme, ale je možné, že nakonec bude proti předchůdci pozměněný v méně věcech než jádro Intelu.

Celkové rysy Lion Cove jsou hodně odlišné, počínaje třeba tím, že Intel opustil unifikovaný scheduler (plánovač rozdělující instrukce mezi jednotky), za nímž byly v jádrech vycházejících z linie architektury P6 přes Conroe a Sandy Bridge napojené všechny vykonávací jednotky – ALU, AGU, i jednotky SIMD (FPU). Naproti tomu jádra AMD nebo již i malá jádra E-Core od Intelu pro ně mají různě rozdělené schedulery. Na tuto koncepci nyní přechází i Lion Cove.
6× ALU
Celočíselná část obsahuje šest ALU (o jednu víc než Golden Cove a zřejmě stejně jako Zen 5) a má teď svůj vlastní integer scheduler. Těchto šest ALU je za porty P0 až P5 a všechny umí obsloužit základní aritmeticko-logické instrukce ALU.

Procesorová architektura Intel Lion Cove – Prezentace z Computexu 2024
Sudé porty umí také zpracovávat větvení (pro to jsou tedy k dispozici tři jednotky „JMP“). Liché porty naopak vedle ALU operací mohou zpracovat operace typu SHIFT a celočíselné násobení (MUL). Jádro tedy všechny tyto operace umí provést tři za cyklus. Jeden port samozřejmě za cyklus může akceptovat jen jednu operaci, nelze v něm využít jak ALU, tak například obsluhu větvení.
6× AGU
Velmi silná je také load-store část, sloužící pro zápisy a čtení do a z paměti. Procesor má separátní memory scheduler pro operace load-store a šest AGU (porty P20, P21, P22, P25, P26, P27), z nichž tři umí obsluhovat načítání (load) a tři zápisy (store). Procesory často mívají část jednotek schopnou obou operací, což vede k lepší zaměstnanosti jednotek ve všech různých zátěžích, protože poměr čtení a zápisů může kolísat. Intel se ale zřejmě rozhodl jinak.
Jednoúčelové jednotky store nebo load jsou patrně menší a úspornější, ale znamená to, že přes přítomnost šesti pipeline lze vždy obsloužit jen maximálně tři zápisy a maximálně tři čtení (více operací jen při kombinaci čtení a zápisů).
Separátně pak ještě stojí dvě pipeline pro operace Store Data, ty jsou na portech P10 a P11. Tyto pipeline mají vlastní store data scheduler.
Poprvé samostatná FPU/SIMD jednotka
Zejména pak má vlastní scheduler (vector scheduler) jednotka FPU, která je s ním oddělená do separátní domény od zbytku jádra, jako to mají třeba zmíněná jádra AMD. Toto umožňuje ji uspat k úspoře energie, ale také lze jádro flexibilněji dál rozvíjet, protože jsou tyto bloky separované. Intel například rozšířil ALU část, ale u části SIMD pipeline nepřidal.
Přesnější je ale mluvit o jednotce SIMD, neboť to je dnes její hlavní použití a instrukce SIMD operují jak s celočíselnými, tak floating-point datovými typy. V jádru Lion Cove směřují oba typy SIMD operací do této jednotky, zatímco v předchozích velkých jádrech Intelu byly vektorové jednotky schované za stejnými porty jako běžné skalární celočíselné ALU. To mělo tu nevýhodu, že použití ALU blokovalo jednotky SIMD na stejném portu a obráceně.

Procesorová architektura Intel Lion Cove – Prezentace z Computexu 2024
Nyní má SIMD či vektorová část čtyři vlastní pipeline s porty V0, V1, V2 a V3, které jsou využitelné paralelně s ALU. Vydělení jednotky SIMD má smysl i proto, že operuje nad vlastními registry (SSE má registry XMM, AVX2 registry YMM a AVX-512 registry ZMM, také legacy instrukce x87 a MMX používají vlastní registry původně určené pro x87 FPU), zatímco ALU pracuje s obecnými registry.
Jak sada obecných, tak sada SIMD registrů má v čipu vlastní fyzický soubor registrů k uložení jejich obsahu. V souladu s tím také ALU část a jednotka SIMD mají vlastní mechanismus přejmenování registrů.
Čtyři pipeline jsou dělané tak, že polovina (V0 a V1) umí obsluhovat operace FMA (tedy fused multiply-accumulate, umí ale také jen sčítání a jen násobení) a vektorové operace SHIFT. Druhá polovina (V2, V3) pak umí jen floating-point sčítání (FADD), ale zase jsou na těchto pipeline/portech k dispozici děličky (FPDIV) a jednotky pro permutace (shuffle operace). Tyto druhy instrukcí je tedy jádro schopné provádět vždy dvě za cyklus (s výjimkou FADD, kde asi půjdou čtyři). Celočíselné operace SIMD jsou však podporované na všech čtyřech pipeline, takže jádro umí zpracovat čtyři za cyklus.

Procesorová architektura Intel Lion Cove – Prezentace z Computexu 2024
Jednotka SIMD by v procesorech Lunar Lake měla pracovat jen se šířkou 256 bitů, tedy podporuje operace SSE–SSE4, AVX a AVX2, ale nikoliv AVX-512, což je opět kvůli kompatibilitě s malými jádry v big.LITTLE procesoru. Serverová verze jádra by však měla podporovat AVX-512, a bude mít asi tedy šířku jednotek 512 bitů.
Je zajímavé, že SIMD pipeline jsou stále jen čtyři jako v předchozím jádru, přestože v ostatních jednotkách se jádro rozšiřovalo. Nicméně oddělení SIMD a ALU operací zvlášť by mohlo vést k zajímavým zlepšením výkonu i přesto, že se šířka SIMD jednotek nezměnila.
Velmi široký frontend s osmi dekodéry
Probíráním vykonávacích jednotek (což je tzv. backend) v prvé řadě jsme nicméně přeskočili obvyklé pořadí věcí. Vraťme se proto k frontendu, kterým zpracování instrukcí začíná a jehož rolí je co nejefektivněji krmit vykonávací jednotky prací ze spouštěného programového kódu – což není vůbec triviální věc, naopak je to asi na dnešních procesorech extrémně složitý a pro výkon kritický problém.
Intel uvádí, že zvětšil (rozšířil) fetch procesoru, čímž se míní fáze načítání části kódu z L1 instrukční cache, nicméně nemáme přesná čísla. Posílena byla také predikce větvení, predikční blok je údajně 8× větší.

Procesorová architektura Intel Lion Cove – Prezentace z Computexu 2024
Instrukční sada x86 je mrtvá, protože…
Lion Cove má osm paralelních instrukčních dekodérů, dokáže tedy dekódovat až osm instrukcí v jednom cyklu. Poněkud se tím tedy boří jedna z manter, kterou často hlásali kritici architektury x86, totiž že její instrukce s proměnlivou délkou znamenají, že x86 procesory nikdy nebudou mít velký počet paralelních dekodérů. A to jim dle této argumentace znemožňuje dosáhnout vysokého IPC, jaké je třeba dosažitelné u procesorů ARM (například u jader od Applu).
Jádro Lion Cove evidentně tuto „nemožnost“ překonává (i když už předchozí Golden Cove mělo dekodérů šest) a také mu v tom zřejmě nezabránilo to, že tyto dekodéry jsou asi skutečně komplexnější a větší na zabranou plochu (a spotřebu) než dekodéry architektury ARM. I když samozřejmě teprve uvidíme z podrobných analýz, jak dobře je jádro schopné tolik dekodérů uplatnit na praktickém běžícím kódu.
Vedle dekodérů může procesor ale dostávat instrukce z uOP cache, která ukládá již dekódované instrukce, které tak není třeba dekódovat znovu, čímž se šetří energie. Z uOP cache může jádro Lion Cove tahat až 12 instrukcí za cyklus, takže v tomto režimu může být ještě výkonnější. Typicky by x86 procesory měly běžet z uOP cache většinu času. Při běhu instrukcí, které jsou mikrokódované, může být k dalšímu zpracování poslána až čtveřice operací za cyklus.
RoB má 576 položek
Také následující fáze alllocate/rename, ve které dochází k přejmenování registrů za cílem eliminace konfliktů v kódu a zvýšení výkonu tím, že se operace mohou provádět nezávisle na sobě, má rozšířenou kapacitu. Projde jí až osm operací za cyklus proti šesti v předchozím jádru. Intel také zvětšil frontu uOP queue co do kapacity a propustnosti a zejména zvětšil Reorder Buffer (RoB), což je fronta tvořící „okno“ instrukcí, nad nímž jádro dokáže provádět out-of-order zpracování kódu.

Procesorová architektura Intel Lion Cove – Prezentace z Computexu 2024
To znamená, že se instrukce provádějí mimo pořadí, pokud na sobě nezávisí. CPU tak například ve chvíli, kdy má volnou jednotku ALU, provede instrukci, která je v kódu až někde dál. Tím se zvyšuje IPC (výkon na 1 MHz frekvence) a funguje to tím lépe, čím větší část kódu přitom procesor vidí.
U Golden Cove už byl RoB docela velký s kapacitou 512 instrukcí (už dekódovaných, čili spíše musíme mluvit o uOPech). Lion Cove ho nezvětšuje úplně radikálně, má RoB o kapacitě 576 operací. Jádro také rozšířilo finální fázi retirement, která zvládne až 12 operací za cyklus místo dřívějších osmi.
Hyper-Threading: Vyhozen pro nadbytečnost
Zásadní novinka jádra Lion Cove, o níž už jsme chvíli věděli, je odebrání Hyper-Threadingu neboli HT (HT je firemní označení používané Intelem, „generické“ označení je SMT). Tato technika zpracovává na jednom jádru současně dvě vlákna. Cíl je takový, že s dvěma vlákny může v mnohovláknových zátěžích jádro využít i ty prostředky (například ALU), které jedno vlákno nedokáže uplatnit.
Celkový výkon extrahovaný z procesoru se tím zvýší, Intel uvádí až o 30 %, takže obě vlákna podávají 65 % výkonu, který by mělo vlákno jediné (přičemž energetická efektivita tohoto zpracování je o trošku lepší, ale spotřeba je o 20 % vyšší). V případě, kdy jádro zpracovává jednovláknovou aplikaci, je druhé vlákno nečinné a ideálně by nemělo ubírat z výkonu, který by tak měl být prakticky na 100 %.
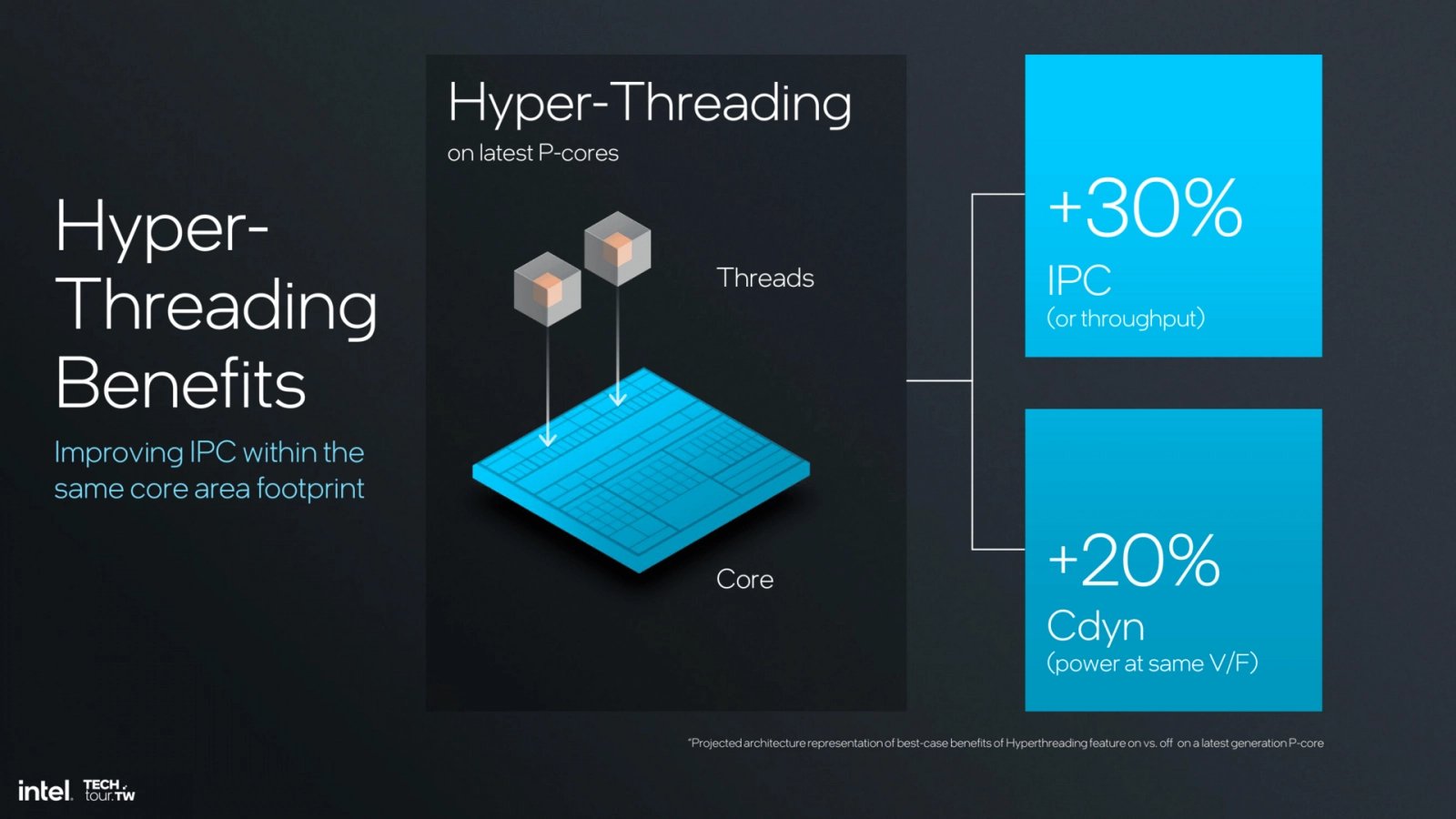
Hyper-Threading podle Intelu přidává cca 30 % výkonu
Nicméně SMT vyžaduje zdvojení řady struktur v jádru, které musí stále hlídat, ke kterému vláknu instrukce (a data v cache) patří. Tato technika proto hodně komplikuje zajištění a ověření korektní funkce procesoru (také na ni míří hodně timing útoků, takže SMT je považováno za problematické pro bezpečnost) a současně také zvětšuje plochu jádra na čipu.
Proč už se HT nehodí?
Obvykle se investice do této plochy navíc považuje za relativně malou vzhledem k tomu, jaké jsou přínosy, nicméně Intel se rozhodl SMT (HT) z jádra odstranit a raději zvolit zjednodušení. Podle firmy tato optimalizace zmenšila jádro o 15 % a výkon při určité dané spotřebě může být o 5 % lepší (otázka je, jestli to ale neplatí jen pro jednovláknové úlohy). Důvodem je to, že Intel nyní vyrábí hybridní procesory, jejichž jádra E-Core mají podobnou funkci a tím se tato řešení trochu duplikují.
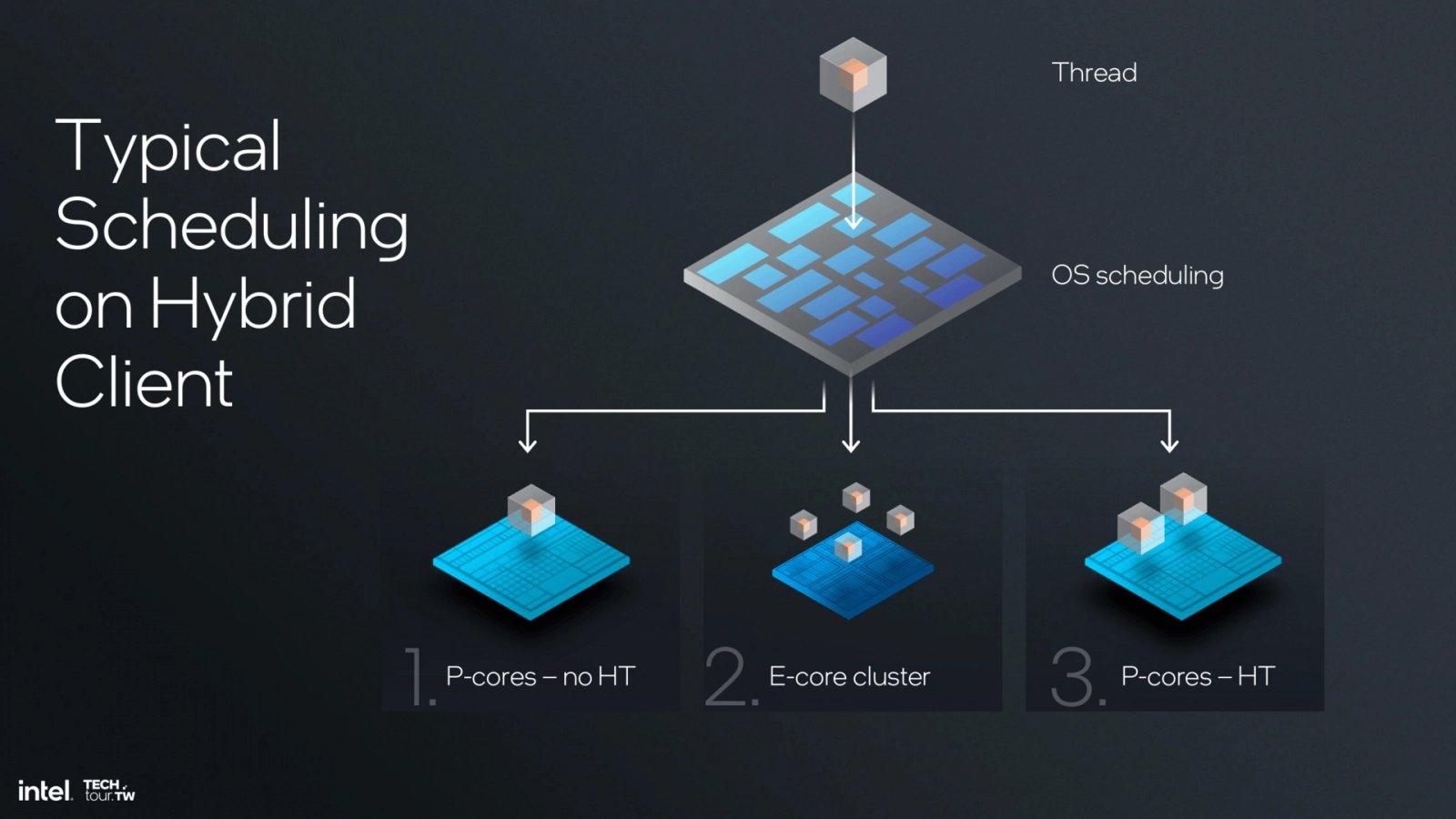
Procesorová architektura Intel Lion Cove – Prezentace z Computexu 2024
Politika procesorů Intel je taková, že mnohovláknová úloha (pro jedno- a málovláknové není HT relevantní) nejprve obsadí P-Core jedním vláknem, pak si další vlákna bere na jádrech E-Core a až v třetí řadě začne obsazovat druhá vlákna na jádrech P-Core. To znamená, že v méně škálujících úlohách SMT/HT dojde k využití méně často než E-Core, což opět přispělo k rozhodnutí se na HT vykašlat. Ovšem ve škálujících úlohách, které dokážou využít všechna vlákna, která se jim nabízí, odebrání HT výkonu procesorů Arrow Lake a Lunar Lake trochu uškodí – jde o kompromis.
Paměti cache zcela po novu, přidaná L0/L1
Intel také předělal systém pamětí cache, který až na konkrétní kapacity fungoval v klientských procesorech dost podobně od architektury Nehalem z roku 2008. Procesor má L0, L1, L2 a L3 cache, plus ještě SLC cache pro celý SoC. Není to design kompletně odznova. L0 cache pro data má kapacitu 48 kB a latenci 4 cykly. Zdá se, že víceméně převzala roli či architekturu předešlé L1 cache, ale není úplně stejná. L1 cache v předchozím jádru měla sice stejnou kapacitu, ale pro většinu operací měla latenci 5 cyklů.
Nové je ale to, co se teď nazývá L1 cache pro data – jde o paměť s kapacitou 192 kB a latencí 9 cyklů, což je poměrně nízká latence (malé L2 cache typicky mívaly latenci 12 cyklů, například v jádrech Zen), asi by se tedy alternativně mohla jmenovat i L1.5 cache.
Tato paměť asi vyrovnává nevýhodu, kterou měla poslední jádra Intelu. Jejich L2 cache totiž Intel neustále zvětšoval (přitom ještě Skylake mělo jen 256kB rychlou L2), zatímco se jim zhoršovala latence, což negovalo část výhody lepší hitrate. V Lion Cove má L2 cache kapacitu 3 MB (ovšem jen 2,5 MB u Lunar Lake) s latencí 17 cyklů. Vejdou se do ní tedy poměrně velké pracovní sady programů, ale přístupy trvají dlouho. Nová L1 cache to kompenzuje tím, že poskytuje menší prostor, ale s rychlostí ještě větší, než mívaly dřívější rychlé L2 cache.

Procesorová architektura Intel Lion Cove – Prezentace z Computexu 2024
Vedle samotných datových cache také Intel u jádra Lion Cove zvětšil TLB pro L0 datovou cache z 96 na 128 položek.
L3 cache má v Lunar Lake kapacitu 12 MB, přičemž zřejmě obsluhuje jen čtveřici velkých jader, nikoliv malá jádra. Je to proto, aby v úsporném režimu, kdy P-Core „spí“, bylo možné vypnout právě i L3 cache a propojovací logiku velkých jader. V procesorech Arrow Lake by to tak ale asi být nemělo, u těch budou E-Core pravděpodobně zase sdílet L3 cache pro lepší výkon.
Frekvence už nebudou skákat po 100 MHz, inteligentnější boost
Lion Cove se liší ještě v jedné věci, která opět asi dokládá, do jaké hloubky zde Intel změnil svou architekturu. Už hodně dlouho (od doby, kdy se přestala používat FSB) se frekvence procesorů Intel u velkých jader měnila po 100 MHz. Podobně, jako AMD u architektury Zen přešlo na 25MHz stupínky, Intel nyní u jádra Lion Cove přešel na granularitu frekvence po 16,66 MHz (tedy 100 MHz bylo rozděleno na 6 dílků).

Procesorová architektura Intel Lion Cove – Prezentace z Computexu 2024
To dovolí jemnější ladění frekvence. Přímo ve specifikacích to nemusí být vidět a pořád mohou být zarovnané na kulaté stovky, ale procesor bude moci nastavovat taky plynuleji a díky větší granularitě také asi obvykle bude schopen nasadit o kousíček lepší takt, než když byl vázaný 100MHz kroky. Mělo by to tedy o trochu zlepšit výkon, ale i energetickou efektivitu.
I automatické řízení frekvence a spotřeby by mělo být pokročilejší. Dosud bylo chování předem definované a dost rigidní. Ale nově se má boost automaticky přizpůsobovat aktuálním podmínkám a snad dosahovat lepšího výkonu, algoritmus by měl být optimalizovaný pomocí AI.
IPC lepší o 14 % proti Meteor Lake
Účelem těchto velkých změn a širokého designu je jak zvýšení výkonu na 1 MHz frekvence (tzv. IPC), tak také poskytnutí základu pro další růst v budoucnu. Intel uvádí, že v nynější verzi architektury, tedy Lion Cove, má toto jádro o zhruba 14 % vyšší IPC než předchozí jádro Redwood Cove.
Pozor – srovnání je tedy proti jádru ve 4nm procesorech Meteor Lake, nikoliv proti jádru v procesorech Alder Lake a Raptor Lake. Redwood Cove podle některých testů může být o trošku horší na 1 MHz, nicméně pořád by proti procesorům Raptor Lake měla tato architektura vykazovat při stejné frekvenci zlepšení výkonu o dvojciferná procenta.
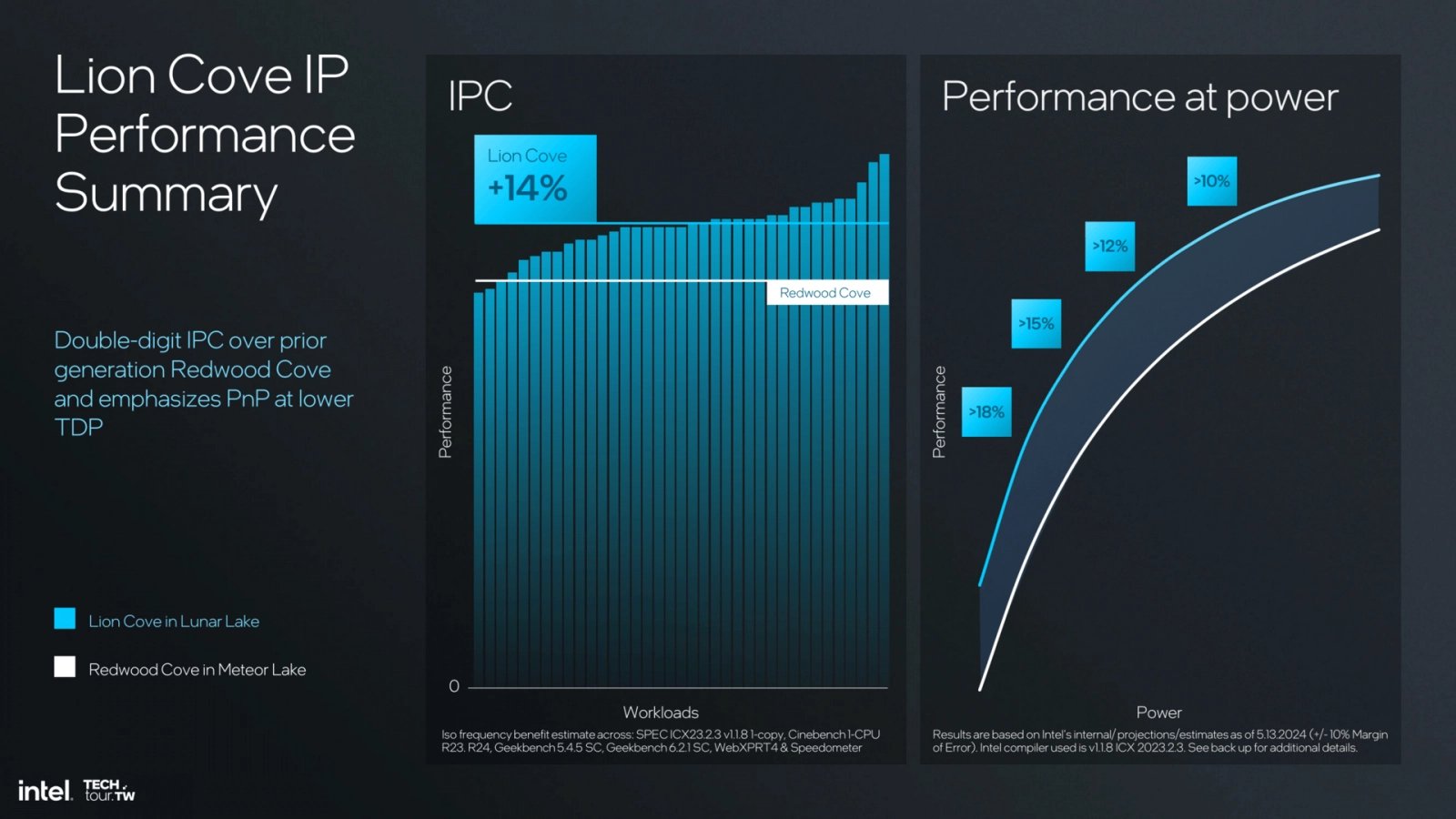
Procesorová architektura Intel Lion Cove – Prezentace z Computexu 2024
Toto číslo je mírně horší, než jaké uvádí AMD u Zenu 5 (+16 %). Nicméně čísla tohoto typu bývají trošku arbitrární, protože závisí na tom, jaké testy se do měření IPC zahrnou. Zda tedy bude v praxi předvádět větší skok ve výkonu Zen 5, nebo Lion Cove, je ještě předčasné diskutovat.

U Lion Cove bude samozřejmě záviset také na frekvencích, které jsou vždy druhým faktorem výkonu důležitým stejně jako IPC. Zatímco Zen 5 by měl mít jak v desktopu (5,7 GHz), tak v noteboocích (5,1 GHz) stejné maximální frekvence jako předchozí generace Zen 4, u procesorů Lunar Lake a Arrow Lake to zatím nevíme.
Došlo u nich k tomu, že místo výrobního procesu Intelu použijí poprvé výrobu u TSMC, což je radikální změna. Bude to již 3nm proces, který by měl být výhodou v energetické efektivitě, ale není jisté, zda nebude omezující pro frekvence, protože Intel má používat zatím jen základní verzi N3B, nikoliv vylepšený proces N3P, který nedávno dovolil významně zvýšit frekvence Applu u procesoru M4.
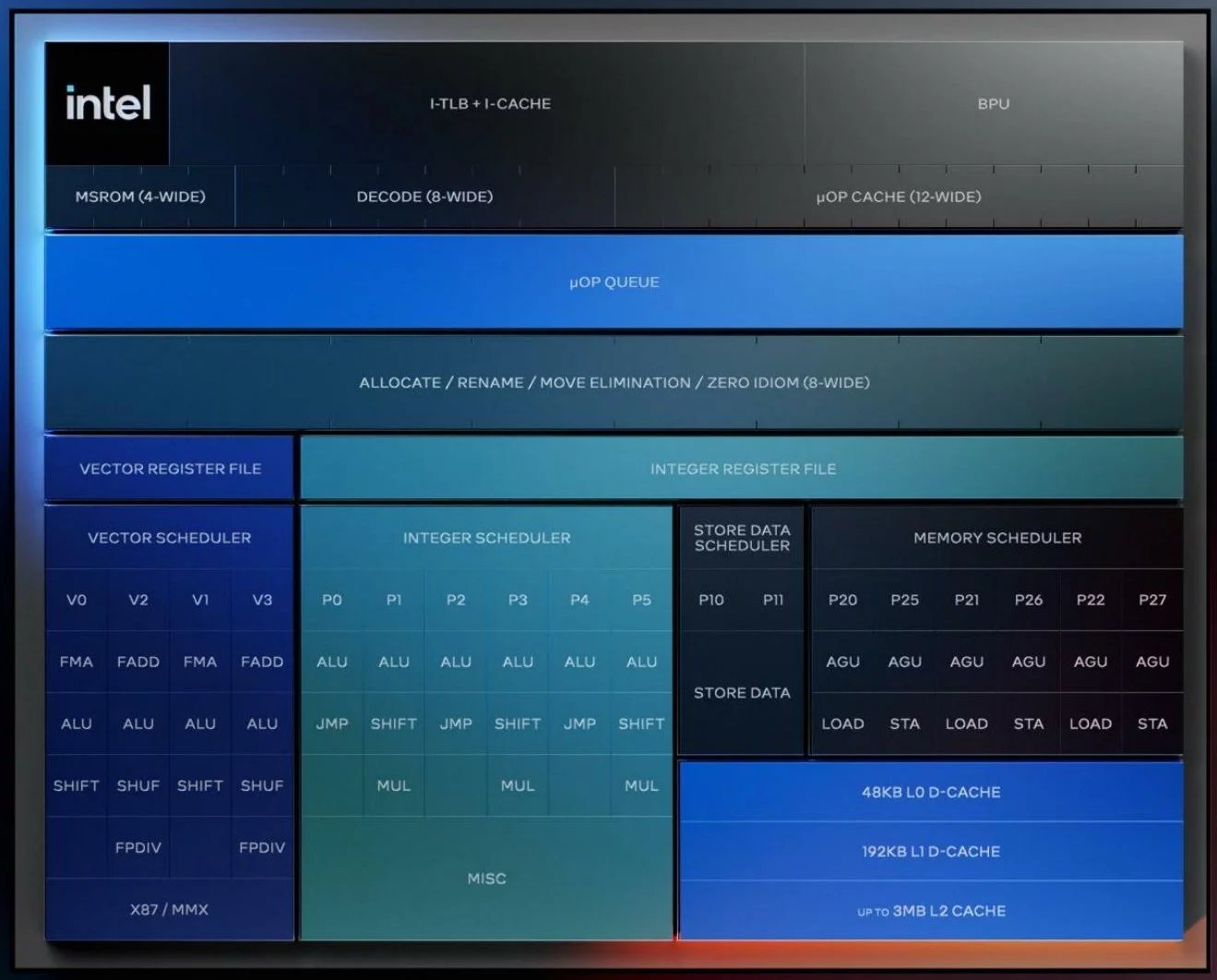
Schéma jádra Lion Cove
I bez ohledu na to, jak úspěšně si Lion Cove povede v benchmarcích, ale jeho architektonické vlastnosti vypadají z toho, co víme, dost pozoruhodně. Intel by se s ním měl významně posunout ve výkonu i energetické efektivitě a dost by mu to mělo pomoci v konkurenceschopnosti (pokud tedy procesor nezabijí nízké maximální frekvence, u těch se teprve uvidí).

Různé předběžné nekrology a soudy o nefunkčnosti firmy možná bude třeba přehodnotit. Vedle procesorů přímo používajících Lion Cove současně tato architektura podobně jako Zen 5 u AMD otevírá potenciál pro další rozvoj.
Zdroje: Intel, AnandTech, Tom’s Hardware

