
S koncem srpna přišla konference Hot Chips představující různé pokročilé procesory a další čipy. A jedním z nich tentokrát je nová generace AI GPU (či akcelerátoru) od Nvidie, který má nahradit loni uvedený (byť v masovějším měřítku dodávaný spíš až letos) akcelerátor B200. Nvidia mu říká B300 nebo také Blackwell Ultra. Toto GPU dál posílí schopnosti Nvidie v akceleraci umělé inteligence, byť není takovým skokem jako původní Blackwell.
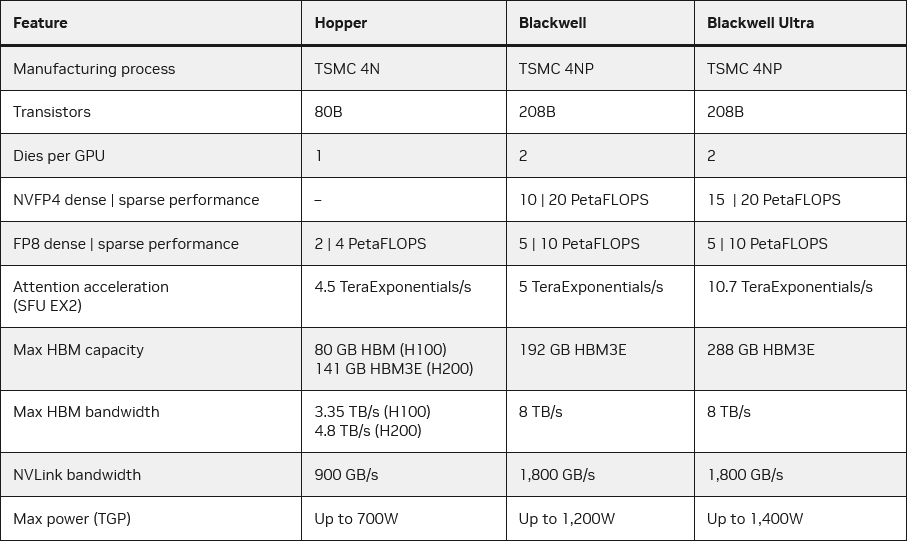
Blackwell Ultra není úplně novou architekturou, jakou Nvidia vydává každé dva roky, což ostatně trochu naznačuje jméno, ale spíše mírnější aktualizací. Nvidia zřejmě vzala původní výpočetní GPU GB200 generace Blackwell a udělala jeho refresh – ale nelze vyloučit, že neprovedla i určité úpravy nebo revize. Takto vzniklé GPU GB300 má podle firmy stále být vyráběno procesem 4NP (což je pro Nvidii upravená verze procesů N5/N4 od TSMC) jako Blackwell. Je stále tvořeno dvěma propojenými čipy a má dokonce mít i stejný počet tranzistorů (nebo aspoň zhruba stejný) jako původní GB200: údajně 208 miliard tranzistorů (104 miliardy v každém z čipů).
Nvidia Blackwell Ultra poprvé představila už na jaře spolu se svou roadmapou, v níž předběžně oznámila i další generace Rubin a Feynman, ale tehdy ještě sdělila jen minimum detailů. Nyní firma na Hot Chips prozradila více.
Nový čip, nebo starý s turbem?
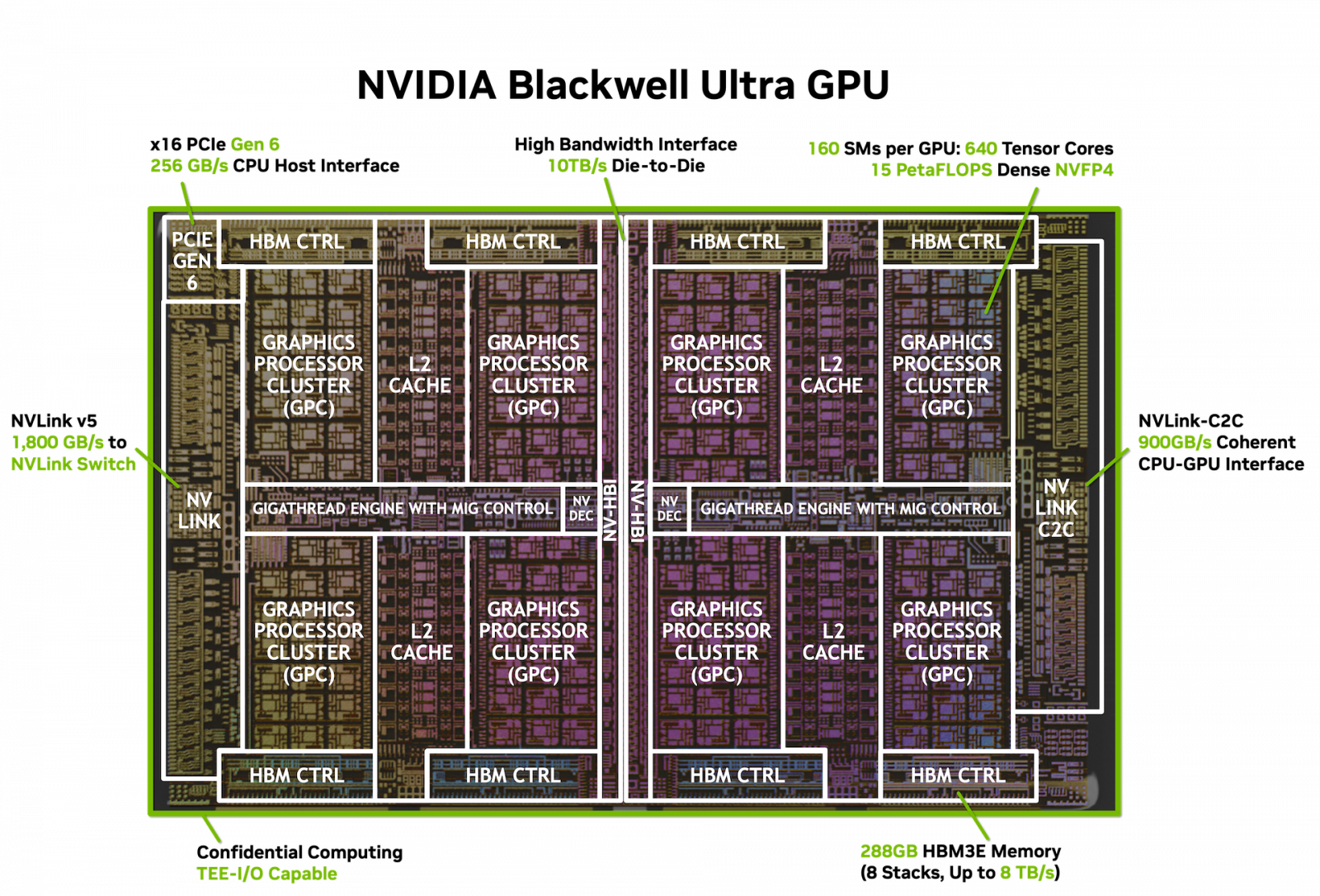
Zatímco GB200 obsahovalo podle Nvidie 144 bloků SM (18 432 shader procesorů či jak Nvidia nepřesně uvádí, „Cuda jader“), nové GB300 zvyšuje počet na 160 SM (20 480 shader procesorů, 640 tensor jader 5. generace). Nevíme ale úplně jistě, zda třeba původní GPU také nemělo vyšší počet a jen nemělo větší procento jednotek v rezervě kvůli výtěžnosti. Je však možné, že Nvidia zmenšila jednotlivé jednotky a v GB300 je jich více při nezměněném celkovém počtu tranzistorů.
Určité reorganizaci výpočetních jednotek nasvědčuje to, že Blackwell Ultra alias GB300 má zřejmě odebránu přímou podporu rychlých výpočtů s dvojitou přesností (FP64) potřebnou pro vědecké výpočty.
Nvidia Blackwell Ultra
Zatímco GB200 podávalo teoreticky výkon 80 TFLOPS ve výpočtech s jednoduchou přesností FP32 a 40 TFLOPS (tedy maximum) v dvojité přesnosti FP64, Blackwell Ultra sice má stále udáván výkon 80 TFLOPS v FP32 (nezměněný), ale výkon v FP64 klesl na pouze 1,3 TFLOPS, což asi znamená, že GPU tyto operace nyní provádí s výkonem na úrovni 1/64 výkonu v FP32.
Blackwell Ultra má i v některých dalších výpočtech uváděný nezměněný výkon. V AI výpočtech s datovými typy FP16 a Bfloat16 na tensor jádrech se uvádí výkon 2,5 PFLOPS nebo 5 PFLOPS s využitím sparsity a totéž u FP8 a FP6, kde je výkon 5 PFLOPS (respektive 10 PFLOPS se sparsity), zase stejně jako u původního Blackwellu.
Nvidia ale uvádí, že se zvýšil výkon v FP4, respektive s datovým typem NVFP4, který je také 4bitový, ale na úrovni většího bloku dat má ještě pro všechny hodnoty uloženou společnou hodnotu škály, která je modifikuje a přidává jim jistou přesnost navíc (ale ne individuálně). Tímto se Nvidia snaží aspoň částečně přiblížit efektivní přesnost parametrů neuronové sítě přesnějších parametrům formátu FP8, ale s nižšími nároky na kapacitu pamětí.
Blackwell Ultra má mít ve 4bitových výpočtech FP4/NVFP4 na tensor jádrech o 50 % vyšší výkon – 15 PFLOPS proti 10 PFLOPS u původního Blackwellu. To je údaj bez použití sparsity, se sparsitou Nvidia uvádí 20 PFLOPS (což je divné, obvykle by číslo mělo být dvojnásobné, 20 PFLOPS měl se sparsitou původní Blackwell).
Porovnání GPU Nvidia Blackwell Ultra s původním Blackwellem a generací Hopper
Tyto zvláštnosti by mohly znamenat, že Nvidia dosahuje vyššího výkonu v FP4 něčím jako je turbo boost u procesorů a herních GPU, kdy v FP4 čip běží na vyšších frekvencích, ale ve výpočtech s vyššími přesnostmi nebo se sparsitou už na to nemá tolik prostoru a proto výkon nestoupá. Blackwell Ultra má mimochodem zvýšené TDP proti původnímu Blackwellu – to z 1200 W stouplo na 1400 W.
288 GB paměti
Možná nejdůležitější upgrade je ale u pamětí. Ty jsou sice stejně rychlé s propustností 8 TB/s, ale Nvidia tentokrát osadila HBM3E s celkovou kapacitou 288 GB (pro oba čipy dohromady), zatímco původní Blackwell měl 192 GB. Toto umožní do GPU nahrávat větší AI modely, což je dnes nejdůležitější parametr pro zlepšování schopností umělé inteligence. Stejnou kapacitu pamětí poskytuje i Instinct MI350X od AMD, uvedený v červnu (a mimochodem již vyráběný modernějším 3nm procesem).

PCI Express 6.0
Blackwell Ultra také nově přidává podporu pro připojení do systému pomocí PCI Expressu 6.0 ×16. Je možné, že hardware pro PCIe 6.0 už měl i původní Blackwell, ale podpora ještě nebyla validována a zapnuta. Nebo nebyla inzerována. V některých materiálech teď už firma uvádí PCIe 6.0 i pro původní GB200 (nejde-li o chybu).
Důležitější bude pro AI systémy asi většinou propojení jednotlivých GPU pomocí rozhraní NVLink – to nicméně má stejnou rychlost jak u původního Blackwellu (Nvidia uvádí souhrnnou propustnost všech rozhraní NVLink dohromady 1,8 TB/s).
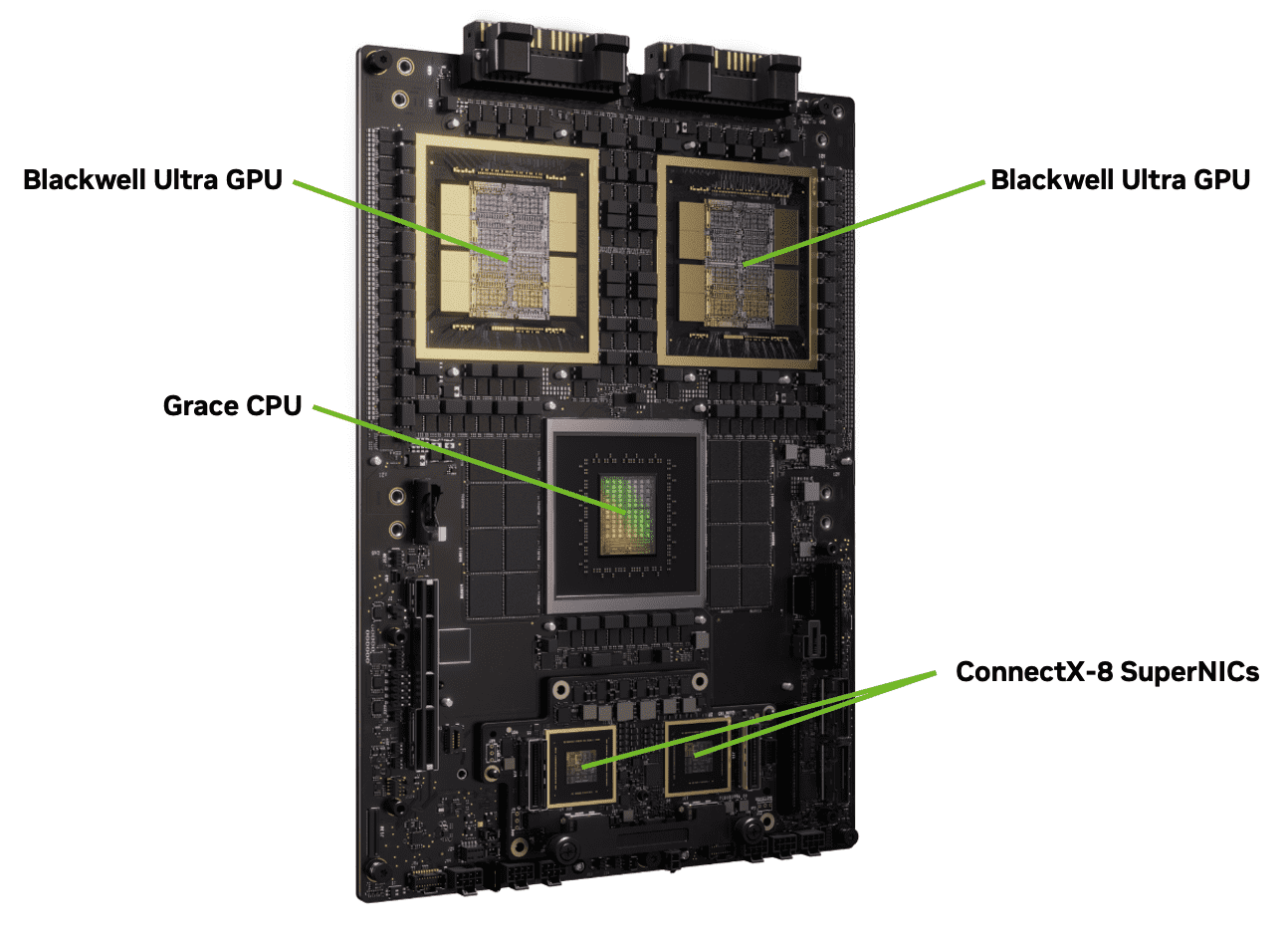
Modul s dvěma GPU Blackwell Ultra, procesorem Nvidia Grace a síťovými adaptéry ConnectX-8
Toto GPU bude opět používáno v systémech třetích stran i vlastních serverech či výpočetních uzlech od Nvidie (systémy HGX). Nvidia bude vyrábět i verzi propojující dvě GPU Blackwell Ultra s procesorem Nvidia Grace.

Blackwell Ultra / GB300 už by podle firmy měl být v sériové výrobě a již ho dostávají zákazníci. Nvidia se také pochlubila, že již má hotový tzv. tape-out GPU následující generace Rubin, která by tak měla být připravena k vydání za nějaký rok či rok a něco. Rubin už bude zase nová architektura a zřejmě také přinese modernější výrobní proces, takže by tato GPU měla být větším skokem než Blackwell Ultra.
Zdroje: Nvidia, ComputerBase, VideoCardz
































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU