V San José v těchto dnech Nvidia pořádá svou konferenci GTC 2025, na které prezentovala různé své novinky a plány do budoucna. Mezi nimi byla i roadmapa budoucích GPU, která odhalila příští generace hardwaru od Nvidie. A to rovnou čtyři, ovšem zatím není jasné, jak se budou realizovat v oblasti herních GPU, roadmapa se totiž soustředí jen na serverová GPU pro trh umělé inteligence a herní grafické karty neodhaluje.
První novinkou Nvidie v datacentrové oblasti následující po současné generaci GPU Blackwell by měl být její refresh nazvaný Blackwell Ultra, kterým firma vyplní prostor mezi dvěma zcela novým generacemi. Nvidia tímto v podstatě přechází na roční cyklus obměny AI GPU, byť tyto refreshové generace nebudou tak významným pokrokem jako plnotučné nové architektury.
Nvidia B300 / Blackwell Ultra
Blackwell Ultra bude prodáván jako GPU označené Nvidia B300 (v porovnání s Blackwellem B200). Tyto akcelerátory mají stále mít architekturu Blackwell jako současná generace, která v posledních měsících po různých problémech s rozjezdem výroby (a údajně někdy i chlazením) přichází na trh. Refreshnutý B300 má podle Nvidie mít o 50 % vyšší teoretický výpočetní výkon v AI operacích – 1,88 PFLOPS ve výpočtech s hodnotami FP32/TF32 na tensor jádrech, 3,75 PFLOPS s hodnotami FP16/Bfloat16, 7,5 PFLOPS v operacích s hodnotami FP8 či FP6 a až 15 PFLOPS v operacích FP4. Toto je samozřejmě na tensor jádrech, s funkcí sparsity pak může být výkon dvojnásobný (u „sparse“ dat a matic samozřejmě).

Nvidia Blackwell Ultra - prezentace na GTC 2025
U pamětí zatím nevíme o tom, že by jejich propustnost měla stoupnout, takže pořád může jít o osm pouzder HB3E s propustností snad 8 TB/s. Má ale narůst kapacita. Zatímco Blackwell B200 je osazen kapacitou 192 GB, Blackwell Ultra B300 bude mít 288 GB paměti pro jedno (dvojčipletové) GPU. Stejnou kapacitu nabídne Instinct MI355X od AMD.
Opět zřejmě půjde o GPU složené ze dvou velkých čipletů. Nvidia neuvádí moc detailů, a tak není jasné, zda jde o nový čip – spíše je asi pravděpodobné nataktování původních GPU na o 50 % vyšší frekvenci. To je hodně velký skok, ale serverová GPU nejsou asi většinou moc limitována frekvenčním stropem, nýbrž spotřebou. Ta byla již u B200 až 1300 W na jedno dvojčipletové GPU, takže u B300 lze čekat hodně velké navýšení spotřeby, má-li být 50% nárůstu výkonu dosaženo pouze skrze zvýšení taktů.
Nvidia by nicméně mohla udělat to, že převede GPU GB200 tvořící čiplet původního Blackwellu na 3nm proces (B200 používá 4nm). To by mohlo otevřít k cestu k 50% navýšení frekvencí i bez nějakého drastického navýšení spotřeby (TDP ale přesto může narůst). Ta by jinak mohla být docela problém, protože Nvidia plánuje nabízet Blackwell Ultra / B300 v rackových jednotkách se 72 GPU (označených „NVL72“), takže jakékoli navýšení spotřeby jednoho GPU se projeví nárůstem spotřeby a koncentrace tepla v celém racku. Je pravděpodobné, že Blackwell Ultra by v takovém případě mohl striktně vyžadovat kapalinové chlazení.

Rack Nvidie s GPU Blackwell Ultra
Blackwell Ultra má údajně být k mání ve druhé polovině roku od Nvidie i dalších výrobců serverů. Instance s těmito GPU mají nabízet i cloudy (Microsoft Azure, Google Cloud, Amazon AWS atd).
2026: Rubin s HBM4
Následující, už úplně nová generace má kódové označení Rubin – že bude použito toto jméno (astronomky Very Rubin), už prosáklo dříve, teď je to tedy oficiálně oznámeno. Tato GPU by měla přijít ve druhé polovině roce 2026, ale je možné, že to bude termín jejich odhalení a startu výroby, zatímco skutečně sériová výroba a komerční dodávky pro široký trh mohou sklouznout až na konec roku nebo do roku 2027 – Nvidia obvykle nové výpočetní produkty odhaluje dost v předstihu.
Nvidia zatím neříká, jaký bude u GPU Rubin použitý výrobní proces (zda 3nm, nebo dokonce už 2nm, ani od jakého dodavatele – nejspíš ale TSMC). Základní verze GPU Rubin bude stejně jako Blackwell B200 tvořena dvěma čiplety a osmi pouzdry paměti, tedy s 8192bitovou sběrnicí, ta už ale bude typu HBM4 a má mít propustnost 13 TB/s. Kapacita má být 288 GB jako u Blackwellu Ultra. GPU má údajně mít 2× rychlejší NVLink a výkon má být údajně 3,3× vyšší než u Blackwellu Ultra (B300) – toto je ale údaj pro celý rack.
Nvidia v generaci Rubin změní značení. Zatímco v generaci Blackwell je rack se 72 GPU (každým tvořeným dvěma GPU čiplety) značený NVL72, v generaci Rubin Nvidia, zdá se, nemíní oficiálně prezentovat dvojčipletový akcelerátor jako jedno unifikované GPU, ale jako dvě. Rackové systémy se 72 těmito akcelerátory se tedy budou jmenovat NVL144, ale půjde o v podstatě totéž, co jsou dnes systémy NVL72.
2027: Rubin Ultra s dvojnásobkem křemíku i socketů, HBM4E
O rok později, v roce 2027, bude i tato generace mít svůj refresh, který Nvidia pojmenovává Rubin Ultra. Je možné, že opět půjde o stejný křemík, ale podle renderů z prezentace a vyjádření firmy bude Rubin Ultra používat dvakrát větší pouzdro, ve kterém už budou čtyři čiplety místo dvou.
Celý akcelerátor bude mít také dvojnásobné množství čipů s pamětí (16, šířka sběrnice 16 384 bitů), která už bude typu HBM4E a má mít celkovou kapacitu 1 TB – použitá HBM4E tedy zřejmě má 64 GB na jedno pouzdro – snad by mohlo jít o pouzdra s 16 vrstvami 32Gb čipů DRAM.

Nvidia Rubin Ultra - prezentace na GTC 2025
Výkon má prý být dokonce 14× vyšší proti Blackwellu Ultra, ovšem toto není při stejném počtu akcelerátorů, jde o údaj pro systém označený NVL576. Ten tedy bude mít zřejmě nejen GPU s dvojnásobným počtem čipletů, ale současně i dvakrát víc celých těchto jednotek (socketů v systému). Fyzická velikost systému pravděpodobně také bude větší a logicky také asi půjde nahoru spotřeba.
(Aktualizováno 20.3. 2025: Jeden jediný NVL576 rack s GPU Rubin Ultra má podle Nvidie mít spotřebu 600 kW.)
Pokud je tedy výkon systému NVL576 s Rubinem Ultra 14× vyšší než u Blackwellu Ultra NVL72 a Rubin NVL144 (ekvivalentní staršímu NVL72) měl nárůst 3,3×, znamená to, že výkon na jeden akcelerátor stoupne u čtyřčipletového Rubinu Ultra 2,12× proti dvojčipletovému základnímu Rubinu. V tomto případě se tedy asi nebudou takty o moc navyšovat, výkon bude z převážné části odpovídat zdvojnásobení čipletů.
2028: Feynman
Nvidia už nakousla i „next-next“ generaci, která má jméno Feynman. Tedy podle známého fyzika, kterého asi netřeba představovat. Tato GPU jsou plánována na rok 2028. K Feynmanovi (Feynmanu?) toho zatím Nvidia ale moc neřekla, nebo přesněji řečeno spíš nic. Opět nevíme, jaký bude použitý výrobní proces, ale ani zda se dále nějak nezmění struktura akcelerátoru, počet čipletů a případně počet socketů v systémech. Nvidia naznačuje, že by mohla být použitá nová generace pamětí, tedy možná HBM5.
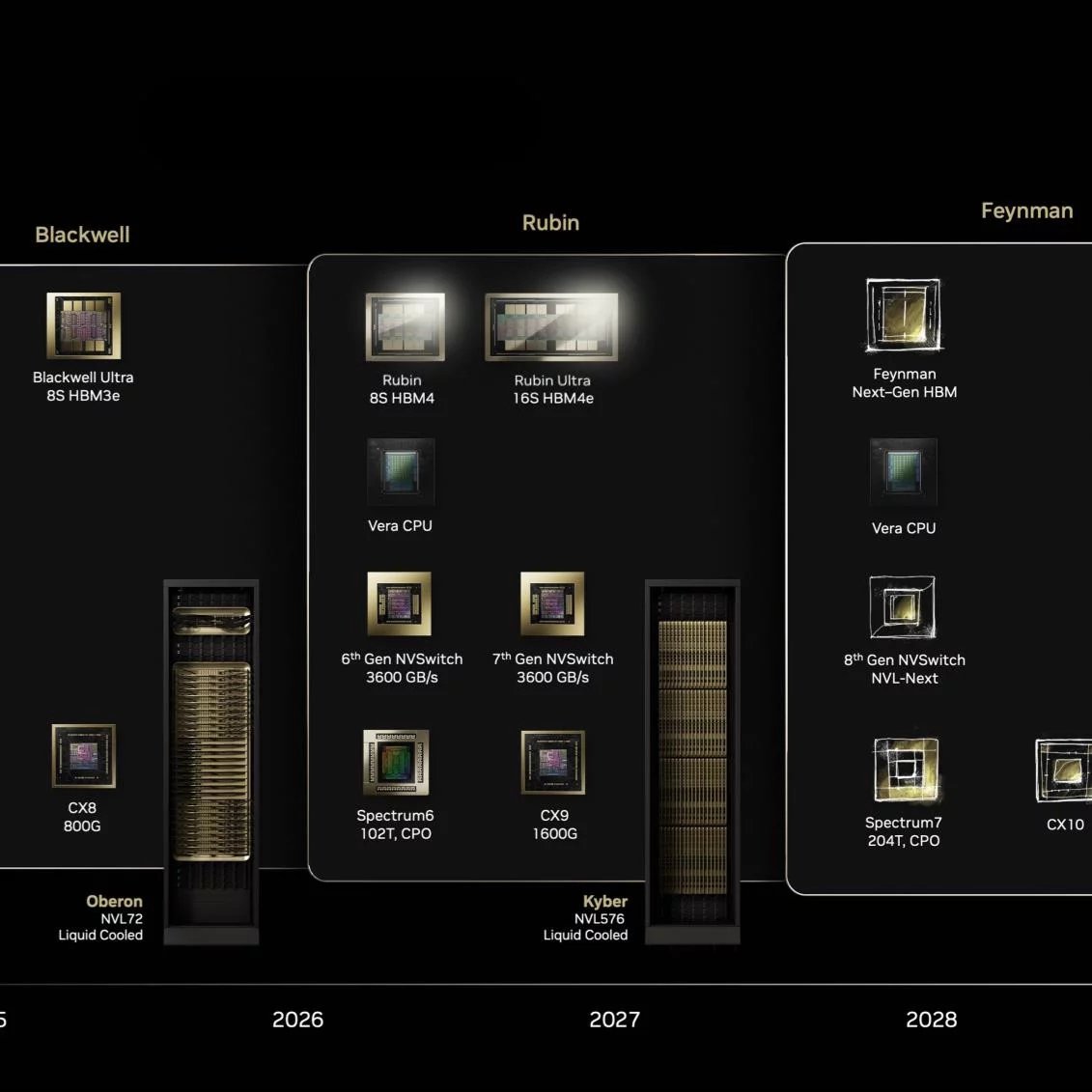
Roadmapa AI GPU a CPU Nvidie na GTC 2025
Tyto čtyři budoucí generace se týkají AI hardwaru. Je dost otázka, zda budou generace Rubin a Feynman mít také svoje odnože v herních GPU, jako je to u Blackwellu. Nvidia někdy architekturu sdílí (nebo aspoň z části, protože mezi herními a výpočetními GPU generací Pascal, Ampere a Blackwell jsou rozdíly), někdy jsou tyto segmenty pokryté odlišně pojmenovanými GPU (Volta a Turing, Hopper a Ada Lovelace).
Bude spotřeba a cena neustále růst?
Nvidia tedy má program do budoucna stále nabitý a zdá se, že plánuje další zvětšování a posilování AI GPU i serverů postavených okolo nich. Pravděpodobně tedy asi také počítá s tím, že dál porostou provozní náklady a ekologický dopad jednotlivého systému (a jednoho GPU), a nejspíš také s tím, že tato GPU budou v přepočtu na jednu jednotku ještě dražší než ta současná. Je ale pravda, že podobný vývoj sledují i řešení konkurentů (a serverová CPU).

Uvidíme, zda to bude trvale platný trend, nebo ekonomické faktory (neboť společnosti, které do těchto systémů nyní investují desítky miliard $, je musí na navázaných AI službách zase nějak vydělat zpátky) vynutí nějaké změny v tomto přístupu. Aktuální finanční výsledky Nvidie vykazují nepřetržitý růst a dosahování dalších a dalších rekordů v tržbách, ale to samozřejmě nemusí znamenat, že to tak bude vždy.